Cómo instalar Apache Spark en Ubuntu 20.04
Apache Spark es un marco de trabajo de código abierto y un sistema de computación en clúster de propósito general. Spark proporciona APIs de alto nivel en Java, Scala, Python y R que soportan gráficos de ejecución general. Viene con módulos incorporados que se utilizan para el streaming, el SQL, el aprendizaje automático y el procesamiento de gráficos. Es capaz de analizar una gran cantidad de datos y distribuirlos por el clúster y procesar los datos en paralelo.
En este tutorial, explicaremos cómo instalar la pila de computación en clúster Apache Spark en Ubuntu 20.04.
Requisitos previos
- Un servidor con Ubuntu 20.04.
- Una contraseña de root configurada el servidor.
Cómo empezar
En primer lugar, tendrás que actualizar los paquetes del sistema a la última versión. Puedes actualizarlos todos con el siguiente comando:
apt-get update -y
Una vez actualizados todos los paquetes, puedes pasar al siguiente paso.
Instalar Java
Apache Spark es una aplicación basada en Java. Por lo tanto, Java debe estar instalado en tu sistema. Puedes instalarlo con el siguiente comando:
apt-get install default-jdk -y
Una vez instalado Java, verifica la versión instalada de Java con el siguiente comando:
java --version
Deberías ver la siguiente salida:
openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)
Instalar Scala
Apache Spark se desarrolla utilizando Scala. Así que tendrás que instalar Scala en tu sistema. Puedes instalarlo con el siguiente comando:
apt-get install scala -y
Después de instalar Scala. Puedes verificar la versión de Scala con el siguiente comando:
scala -version
Deberías ver la siguiente salida:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Ahora, conéctate a la interfaz de Scala con el siguiente comando:
scala
Deberías obtener la siguiente salida:
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8). Type in expressions for evaluation. Or try :help.
Ahora, comprueba el Scala con el siguiente comando:
scala> println("Hitesh Jethva")
Deberías obtener la siguiente salida:
Hitesh Jethva
Instalar Apache Spark
En primer lugar, tendrás que descargar la última versión de Apache Spark desde su sitio web oficial. En el momento de escribir este tutorial, la última versión de Apache Spark es la 2.4.6. Puedes descargarla en el directorio /opt con el siguiente comando:
cd /opt
wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
Una vez descargado, extrae el archivo descargado con el siguiente comando:
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgz
A continuación, cambia el nombre del directorio extraído por el de spark, como se muestra a continuación:
mv spark-2.4.6-bin-hadoop2.7 spark
A continuación, tendrás que configurar el entorno de Spark para poder ejecutar fácilmente los comandos de Spark. Puedes configurarlo editando el archivo .bashrc:
nano ~/.bashrc
Añade las siguientes líneas al final del archivo:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Guarda y cierra el archivo y luego activa el entorno con el siguiente comando:
source ~/.bashrc
Iniciar el servidor maestro Spark
En este punto, Apache Spark está instalado y configurado. Ahora, inicia el servidor maestro Spark con el siguiente comando:
start-master.sh
Deberías ver la siguiente salida:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.out
Por defecto, Spark está escuchando en el puerto 8080. Puedes comprobarlo con el siguiente comando:
ss -tpln | grep 8080
Deberías ver la siguiente salida:
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249))
Ahora, abre tu navegador web y accede a la interfaz web de Spark utilizando la URL http://your-server-ip:8080. Deberías ver la siguiente pantalla:
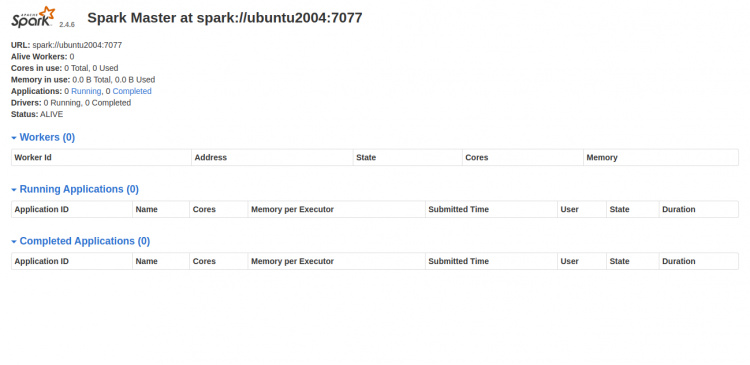
Iniciar el proceso de trabajo de Spark
Como puedes ver, el servicio maestro de Spark se está ejecutando en spark://tu-servidor-ip:7077. Así que puedes utilizar esta dirección para iniciar el proceso de trabajador de Spark utilizando el siguiente comando:
start-slave.sh spark://your-server-ip:7077
Deberías ver la siguiente salida:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.out
Ahora, ve al panel de control de Spark y actualiza la pantalla. Deberías ver el proceso Spark worker en la siguiente pantalla:
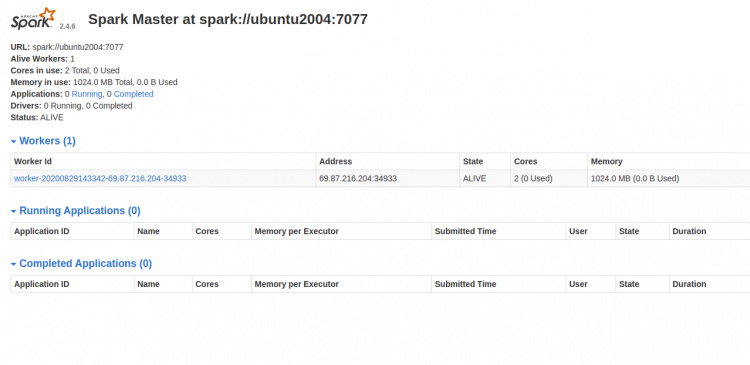
Trabajar con Spark Shell
También puedes conectar el servidor Spark utilizando la línea de comandos. Puedes conectarlo utilizando el comando spark-shell como se muestra a continuación:
spark-shell
Una vez conectado, deberías ver la siguiente salida:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:35:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ubuntu2004:4040
Spark context available as 'sc' (master = local[*], app id = local-1598711719335).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Si quieres utilizar Python en Spark. Puedes utilizar la utilidad de línea de comandos pyspark.
Primero, instala la versión 2 de Python con el siguiente comando:
apt-get install python -y
Una vez instalado, puedes conectar el Spark con el siguiente comando:
pyspark
Una vez conectado, deberías obtener la siguiente salida:
Python 2.7.18rc1 (default, Apr 7 2020, 12:05:55)
[GCC 9.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:36:40 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 2.7.18rc1 (default, Apr 7 2020 12:05:55)
SparkSession available as 'spark'.
>>>
Si quieres detener el servidor maestro y el esclavo. Puedes hacerlo con el siguiente comando:
stop-slave.sh
stop-master.sh
Conclusión
Enhorabuena! has instalado con éxito Apache Spark en el servidor Ubuntu 20.04. Ahora deberías poder realizar pruebas básicas antes de empezar a configurar un cluster de Spark. No dudes en preguntarme si tienes alguna duda.