Configuración de AWS Redshift para el almacenamiento de datos en la nube
En este tutorial, explicaré y guiaré cómo configurar AWS Redshift para utilizar el almacenamiento de datos en la nube. Redshift es un servicio de almacén de datos de petabytes totalmente gestionado que Amazon Web Services está introduciendo en la nube. Funciona combinando uno o más conjuntos de recursos informáticos llamados nodos, organizados en un grupo, un clúster. Cada clúster ejecuta un motor Redshift y puede contener una o más bases de datos. La arquitectura puede elaborarse básicamente de la siguiente manera
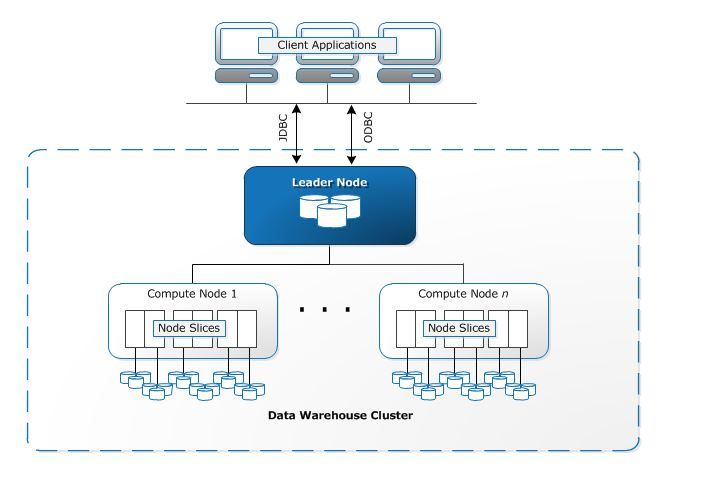
1. Cómo funciona
Básicamente, Redshift se basa en PostgreSQL como motor principal, por lo que la mayoría de las aplicaciones SQL pueden funcionar con Redshift. Redshift también puede integrarse con una amplia gama de aplicaciones, como herramientas de BI, análisis y ETL (Extract, Transform, Load) que permiten a los analistas o ingenieros trabajar con los datos que contiene.
Cuando un usuario configura un almacén de datos de Amazon Redshift, dispone de una topología central para las operaciones denominada clúster. Un clúster de Redshift está compuesto por 1 o más nodos de computación. Si el usuario decide utilizar más de un nodo de computación, Redshift inicia automáticamente un nodo líder. Este nodo líder está configurado para recibir solicitudes y comandos del lado de la ejecución del cliente y no es facturado por AWS.
Las aplicaciones de los clientes sólo se comunican con el nodo líder. Los nodos de cálculo bajo el nodo líder son transparentes para el usuario. Cuando los clientes ejecutan una consulta, el nodo líder analiza la consulta y crea un plan de ejecución óptimo para la ejecución en los nodos de cálculo, teniendo en cuenta la cantidad de datos almacenados en cada nodo.
En este tutorial, te mostraré cómo instalar y configurar Redhift para nuestro propio uso. En este ejemplo, crearé una cuenta y empezaré con el paquete de nivel gratuito.
2. Fase de configuración
2.1 Requisitos previos
Antes de empezar a configurar un clúster de Amazon Redshift, hay un cierto requisito previo que hay que completar.
En primer lugar, regístrate en AWS y, una vez hecho esto, ve al servicio IAM para crear un rol que podamos utilizar para el uso de Redshift. Puedes seguir la captura de pantalla que se muestra a continuación:





Una vez hecho esto, deberías obtener una captura de pantalla como la que se muestra a continuación indicando que el rol se ha creado con éxito.
2.2 Establecer la configuración de Redshift
Como los requisitos previos están hechos, podemos proceder a crear nuestro propio clúster de Redshift. Busca las funciones de Redshift en el panel de búsqueda y procede desde allí. A continuación se muestran las capturas de pantalla de ejemplo:
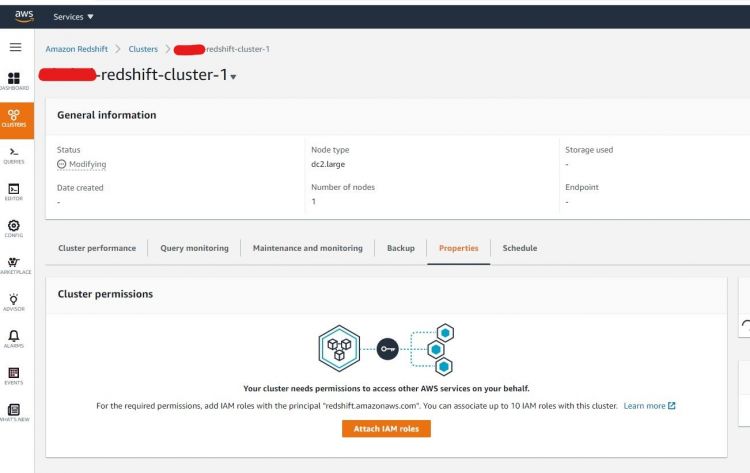
Haz clic en el botón Crear Cl uster y procede con las variables necesarias, ten en cuenta que en la parte de Permisos del Cl uster incluimos nuestro rol IAM que hemos creado previamente.



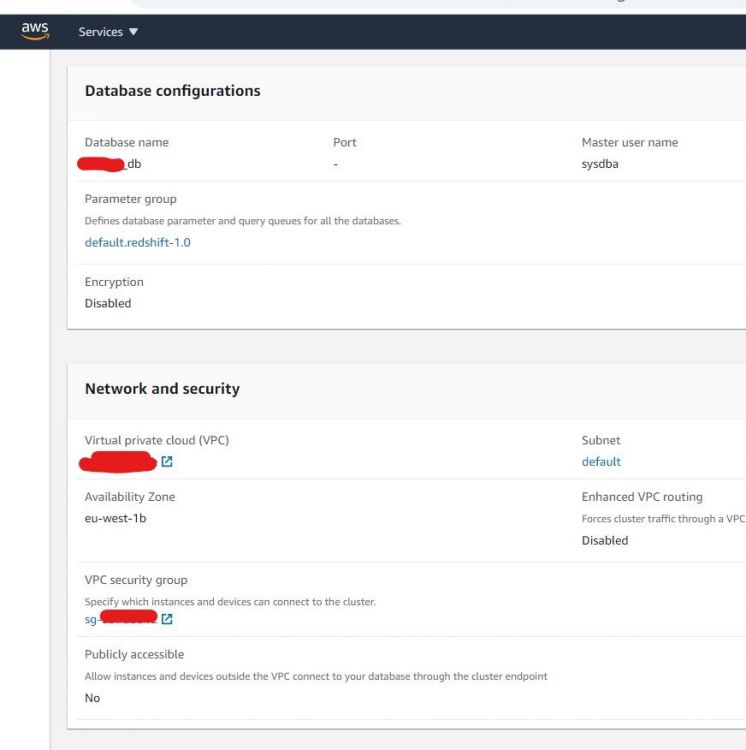
Una vez hecho esto, deberías acabar en el panel de control de redshift como en el caso anterior. Para este tutorial, desactivaremos la capa de seguridad de la red cambiando el grupo de seguridad. Para ello, ve a la parte inferior del panel de control y añade el puerto de Redshift en la pestaña de Entrada. A continuación se muestra un ejemplo:

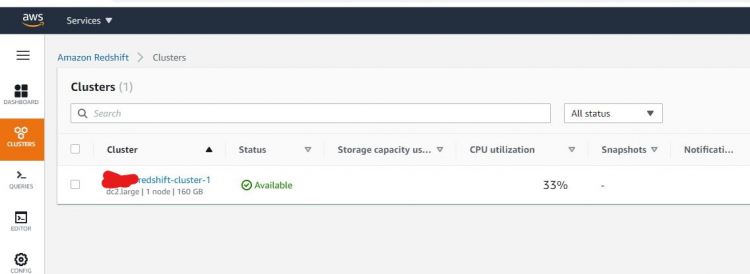
Una vez hecho todo, deberías ver que el nuevo cluster que has creado está ahora disponible para ser utilizado.
3. Fase de pruebas
Ahora, vamos a intentar acceder a nuestro almacén de datos. Para probarlo, haz clic en EDITOR en el panel izquierdo, incluye las variables necesarias y haz clic en Conectar con la base de datos
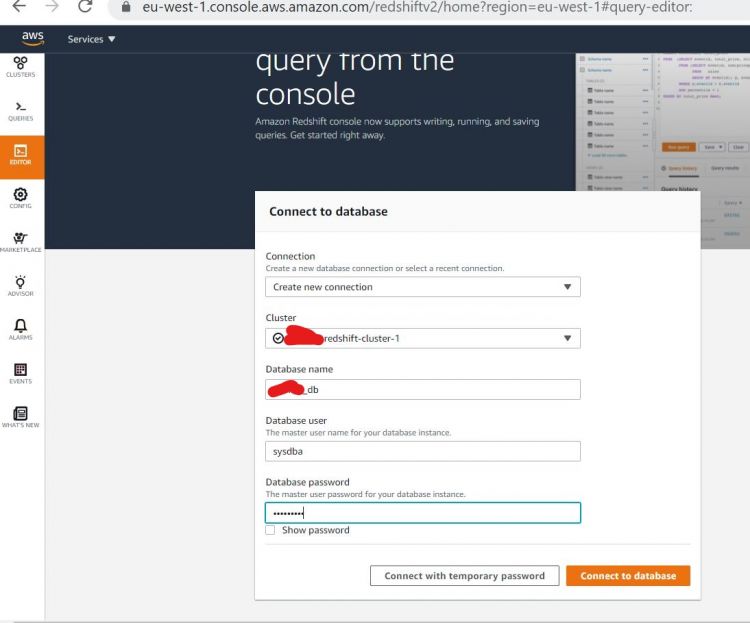
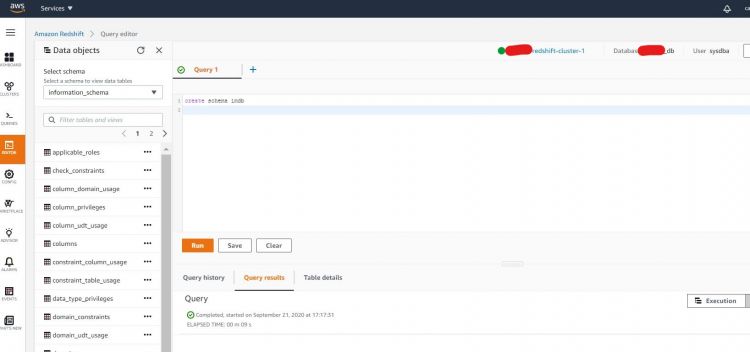
Deberías ser llevado a una página del editor, ahora vamos a empezar por crear nuestro propio esquema de pruebas. Crea un esquema como se indica a continuación y ejecútalo.
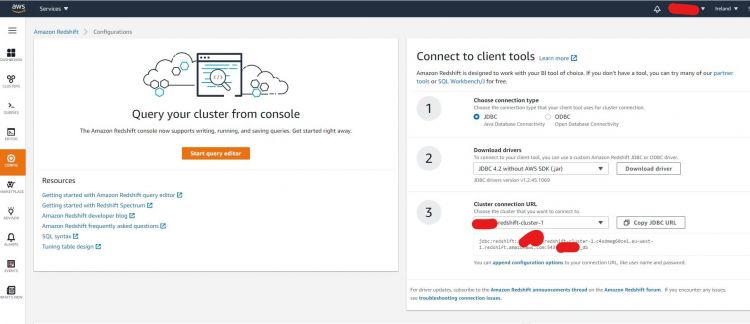
Genial, ahora vamos a probar en el lado local del cliente. Para ello, necesitas obtener la conexión JDBC u ODBC del lado de Redshift. Para obtener esa información, haz clic en el botón Config en el panel izquierdo del tablero.
Elige el tipo de conexión que prefieras y, a continuación, descarga las librerías necesarias y copia la URL como se muestra en el siguiente ejemplo:
A continuación, abre cualquiera de tus herramientas de cliente SQL e introduce las variables de conexión necesarias. En nuestro ejemplo, estamos utilizando una herramienta cliente SQL llamada DBeaver que puedes obtener desde aquí
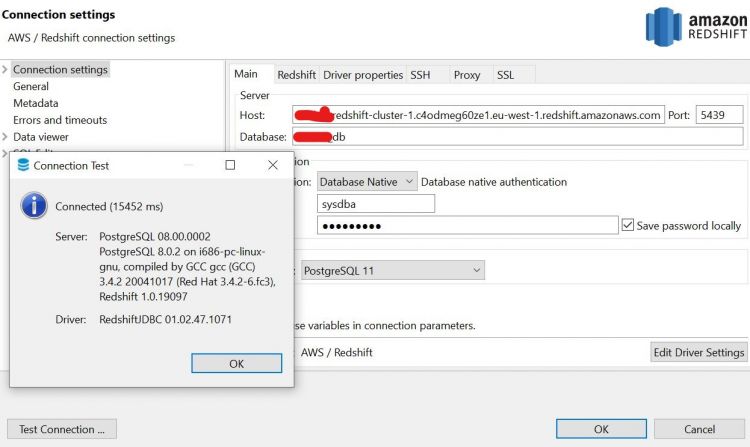
Tu conexión debería tener éxito como se esperaba. Si en algún caso te encuentras con un problema de autenticación, comprueba la configuración realizada en el grupo de seguridad de AWS para obtener más detalles.
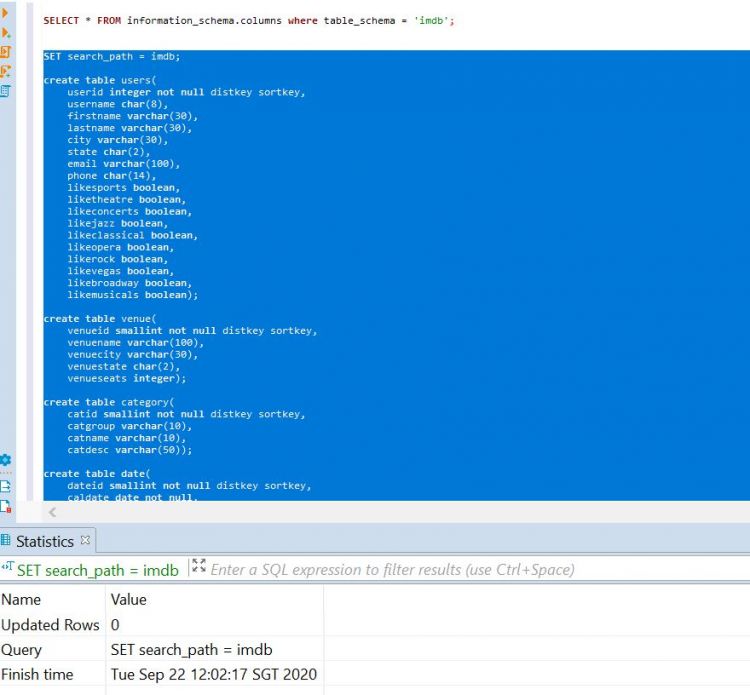
A continuación, vamos a crear un conjunto de tablas bajo nuestro anterior esquema recién creado. A continuación se muestra un ejemplo de creación de tablas que ejecutaremos en nuestro cluster:
SET search_path = imdb;
create table users(
userid integer not null distkey sortkey,
username char(8),
firstname varchar(30),
lastname varchar(30),
city varchar(30),
state char(2),
email varchar(100),
phone char(14),
likesports boolean,
liketheatre boolean,
likeconcerts boolean,
likejazz boolean,
likeclassical boolean,
likeopera boolean,
likerock boolean,
likevegas boolean,
likebroadway boolean,
likemusicals boolean);
create table venue(
venueid smallint not null distkey sortkey,
venuename varchar(100),
venuecity varchar(30),
venuestate char(2),
venueseats integer);
create table category(
catid smallint not null distkey sortkey,
catgroup varchar(10),
catname varchar(10),
catdesc varchar(50));
create table date(
dateid smallint not null distkey sortkey,
caldate date not null,
day character(3) not null,
week smallint not null,
month character(5) not null,
qtr character(5) not null,
year smallint not null,
holiday boolean default('N'));
create table event(
eventid integer not null distkey,
venueid smallint not null,
catid smallint not null,
dateid smallint not null sortkey,
eventname varchar(200),
starttime timestamp);
create table listing(
listid integer not null distkey,
sellerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
numtickets smallint not null,
priceperticket decimal(8,2),
totalprice decimal(8,2),
listtime timestamp);
create table sales(
salesid integer not null,
listid integer not null distkey,
sellerid integer not null,
buyerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
qtysold smallint not null,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp);
El resultado esperado se mostrará como el siguiente :-

A continuación, vamos a intentar cargar datos de muestra en nuestro almacén de datos. Para este ejemplo, he cargado una muestra de datos en mi propio cubo S3 y luego he utilizado el siguiente script para copiar los datos del archivo S3 en Redshift.
copy sales from 's3://shahril-redshift01-abcde/sales_tab.txt'
iam_role 'arn:aws:iam::325581293405:role/shahril-redshift-s3-ro-role'
delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS' region 'eu-west-1';
copy dates from 's3://shahril-redshift01-abcde/date2008_pipe.txt'
iam_role 'arn:aws:iam::325581293405:role/shahril-redshift-s3-ro-role'
delimiter '|' region 'eu-west-1';
Si durante la carga te encuentras con algún problema, puedes consultar la tabla del diccionario de Redshift llamada stl_load_errors como se indica a continuación para obtener una pista del problema.
select * from stl_load_errors ;

Por último, una vez que todo esté hecho, deberías poder extraer y manipular los datos utilizando cualquier función SQL proporcionada. A continuación se muestran algunos de los scripts de ejemplo de las consultas que he utilizado para nuestro ejemplo.
-- Get definition for the sales table.
SELECT *
FROM pg_table_def
WHERE tablename = 'sales';
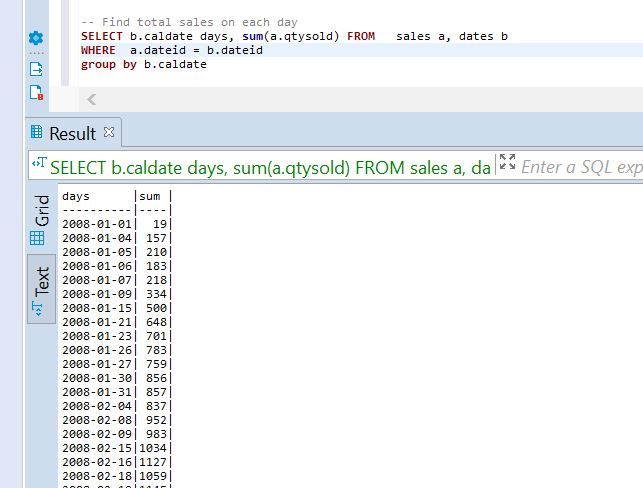
-- Find total sales on each day
SELECT b.caldate days, sum(a.qtysold) FROM sales a, dates b
WHERE a.dateid = b.dateid
group by b.caldate ;
-- Find top 10 buyers by quantity.
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales
GROUP BY buyerid
ORDER BY total_quantity desc limit 10) Q, users
WHERE Q.buyerid = userid
ORDER BY Q.total_quantity desc;
-- Find events in the 99.9 percentile in terms of all time gross sales.
SELECT eventname, total_price
FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) Q, event E
WHERE Q.eventid = E.eventid
AND percentile = 1
ORDER BY total_price desc;
Ya hemos configurado con éxito nuestro propio clúster de Redshift para su uso en el almacenamiento de datos. A continuación, veremos cómo combinar los datos existentes en el Cluster de Redshift con cualquier archivo plano utilizando Redshift Spectrum.