Gestionar las operaciones en el Bucket S3 usando aws-cli desde la instancia EC2
Podemos crear y administrar el cubo de S3 utilizando la consola de AWS. A veces puede surgir la necesidad de crear y realizar operaciones en el cubo S3 desde la línea de comandos. Si no conoces el cubo S3 y quieres aprender sobre él, haz clic aquí donde puedes encontrar un artículo sobre el cubo S3 escrito por mí.
Antes de continuar con este artículo asumo que estás familiarizado con el cubo S3.
En este artículo, veremos los pasos y comandos para crear un cubo S3 desde la línea de comandos y realizar operaciones básicas en él como copiar archivos, sincronizar archivos, etc.
Requisitos previos
- Cuenta de AWS (Créalasi no tienes una).
- Conocimiento básico de los cubos S3(Haz clic aquí para saber más sobre los cubos S3).
- Instancia EC2 de Ubuntu 20.04 (Haz clic aquí para conocer la instancia EC2 y los pasos para crearla desde la consola de AWS. Puedes elegir una AMI de Ubuntu 20.04 en lugar de la 18.04).
- Rol IAM con la política S3FullAccess adjunta (Haz clic aquí para aprender acrear un rolIAM ).
¿Qué vamos a hacer?
- Entra en la cuenta de AWS.
- Instala aws-cli.
- Adjunta un Rol IAM a la instancia EC2.
- Crea un Bucket con aws-cli.
- Realiza la operación básica en el Bucket S3 utilizando aws-cli.
Iniciar sesión en AWS
Antes de proceder a la instalación del comando aws-cli en una instancia EC2, vamos a iniciar sesión en nuestra cuenta.
Haz clic aquí para ir a la página de inicio de sesión de AWS.
Al pulsar el enlace anterior verás la página de inicio de sesión como se indica a continuación.
Una vez que inicies la sesión con éxito en tu cuenta, verás el panel principal de AWS como se muestra a continuación.
Instala aws-cli
Conéctate a tu instancia AWS EC2.
Primero vamos a actualizar el repositorio.
sudo apt-get update
Instala el comando aws-cli utilizando el siguiente comando en el servidor Ubuntu.
sudo apt install awscli
Toma la versión del comando aws-cli.
aws --version
Hasta este momento, sólo tenemos una instancia EC2 sin ningún rol IAM necesario unido a ella.
Ahora si intentamos comprobar la identidad utilizando el siguiente comando se nos pedirá que configuremos las credenciales que se utilizarán para realizar cualquier operación.
aws sts get-caller-identity

Adjunta un Rol IAM a la instancia EC2.
Ve a la consola de AM en tu cuenta de AWS y comprueba si la regla tiene la política requerida adjuntada.
Aquí puedes ver que el rol tiene adjuntada la política AmazonS3FullAccess.

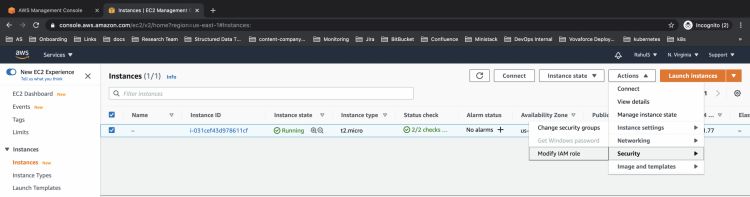
Ahora, ve a la consola de EC2 a y selecciona la instancia que estás utilizando para realizar operaciones en el cubo S3.
Aquí, haz clic en Acciones –> Seguridad –> Modificar rol IAM para adjuntar una regla a la instancia.
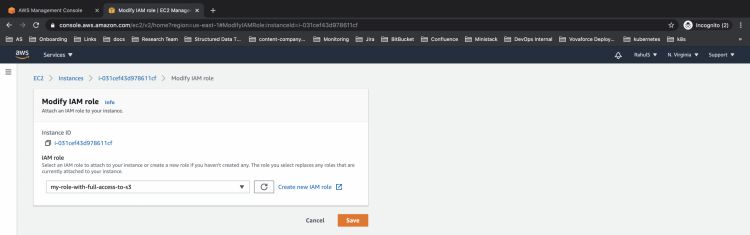
Verás la pantalla en la que puedes seleccionar la regla a adjuntar de la lista desplegable. Haz clic en guardar para continuar.
Realiza la operación básica en S3 Bucket usando aws-cli
Volvamos al terminal de EC2 y ejecutemos el siguiente comando.
aws sts get-caller-identity

Como hemos adjuntado la regla necesaria a la instancia, al ejecutar el comando anterior para comprobar la identidad del rol que se está utilizando para realizar las operaciones desde el terminal, podemos ver el ID de usuario, la cuenta y su ARN en respuesta. Esto significa que hemos autenticado con éxito nuestra instancia EC2. Ahora estamos preparados para realizar operaciones desde el terminal utilizando el rol asociado a la instancia EC2.
Para comprobar los S3 Buckets existentes en la Cuenta AWS, ejecuta el siguiente comando
aws s3 ls
Vamos a crear un nuevo bucket llamado «rahul-new-bucket-dec-2020». Asegúrate de que el nombre del bucket debe ser globalmente único.
aws s3 mb s3://rahul-new-bucket-dec-2020
Ahora, de nuevo, si listamos los cubos podemos ver que se ha creado con éxito un nuevo cubo y que está disponible en la lista de cubos existentes.
aws s3 ls
Vamos a crear un nuevo archivo en nuestra máquina local
touch file-for-s3
Podemos copiar archivos de nuestra máquina local al cubo de S3
aws s3 cp file-for-s3 s3://rahul-new-bucket-dec-2020
Incluso podemos listar el contenido del cubo de S3
aws s3 ls s3://rahul-new-bucket-dec-2020
De la misma manera que copiamos archivos de la máquina local al cubo de S3, también podemos sincronizar un directorio local con el cubo.
La sincronización no copia los archivos y carpetas existentes de la máquina local al cubo. Sólo copia los archivos que se han creado o modificado recientemente
Vamos a crear un nuevo archivo llamado nuestra máquina local
touch new-file
La vez que usaremos la sincronización.
aws s3 sync . s3://rahul-new-bucket-dec-2020
Ahora vamos a crear de nuevo un nuevo archivo
touch file-after-sync
Ahora puedes ver que si sincronizamos de nuevo, sólo se copian los archivos recién creados. Los archivos que ya se han copiado en el cubo no se copian.
aws s3 sync . s3://rahul-new-bucket-dec-2020
Pero este no es el caso de la opción de copia. Se copian todos los archivos, independientemente de los que estén disponibles en S3.
aws s3 cp . s3://rahul-new-bucket-dec-2020 --recursive
Consulta la siguiente captura de pantalla para entender los comandos que acabamos de probar.
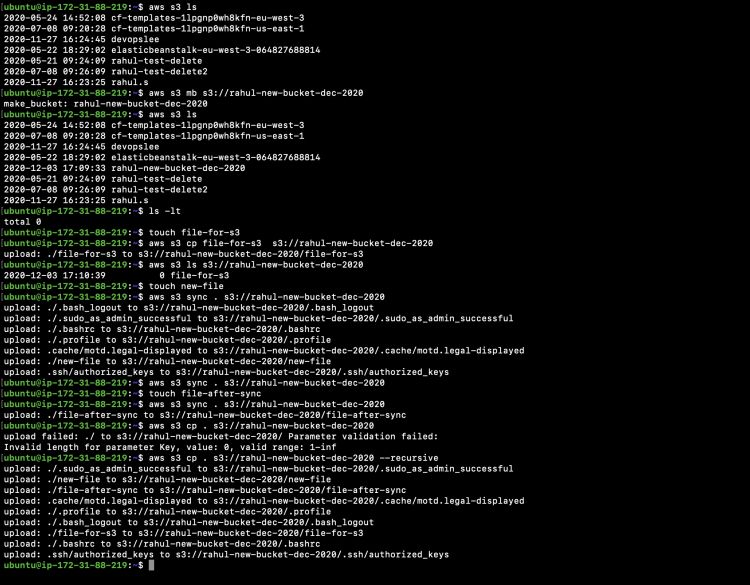
Vamos a comprobar qué archivos están disponibles en nuestro cubo de S3.
aws s3 ls s3://rahul-new-bucket-dec-2020
Podemos eliminar un archivo concreto del cubo de S3 utilizando el subcomando «rm».
aws s3 rm s3://rahul-new-bucket-dec-2020/new-file
Comprueba si el archivo ha sido eliminado o no del bucket
aws s3 ls s3://rahul-new-bucket-dec-2020
Podemos incluso eliminar todos los objetos del cubo utilizando la opción –recursiva
aws s3 rm s3://rahul-new-bucket-dec-2020 --recursive
Comprueba si los objetos se han eliminado del cubo o no
aws s3 ls s3://rahul-new-bucket-dec-2020
Consulta la siguiente captura de pantalla para entender las operaciones que acabamos de realizar.
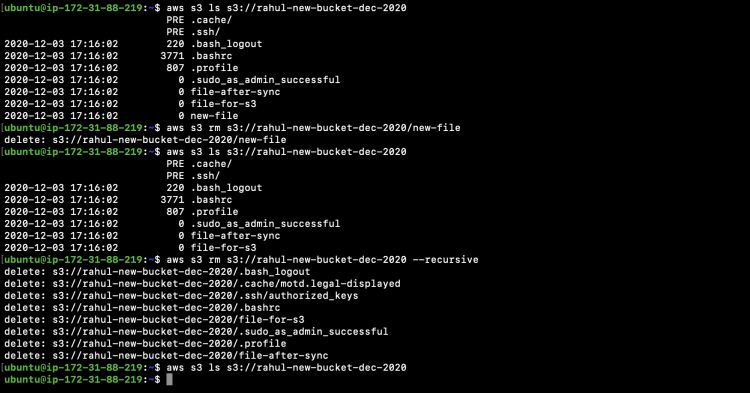
De la misma manera que hemos podido eliminar objetos del cubo, también podemos eliminar el propio cubo
Primero, haz una lista de todos los cubos disponibles en la cuenta.
aws s3 ls
Elimina el cubo deseado utilizando el subcomando «rb».
aws s3 rb s3://rahul-new-bucket-dec-2020
Podemos ver que el cubo especificado se ha eliminado de la cuenta ahora
aws s3 ls
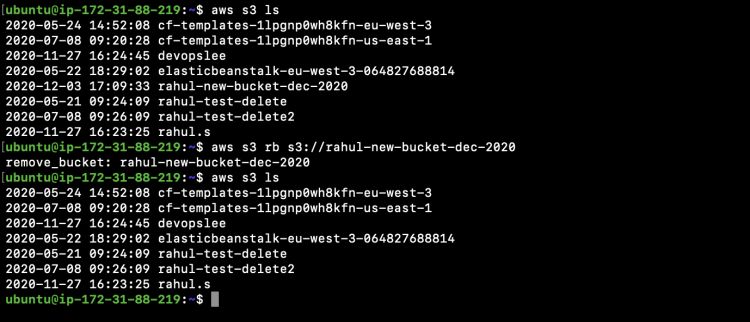
Podemos eliminar la regla que habíamos adjuntado a la instancia para que ésta ya no pueda autorizarse a sí misma.
Para eliminar la regla adjunta ve a la instancia EC2, haz clic en Acciones –> Seguridad –> Modificar rol IAM y elimina la regla que estaba adjunta y guarda la configuración.
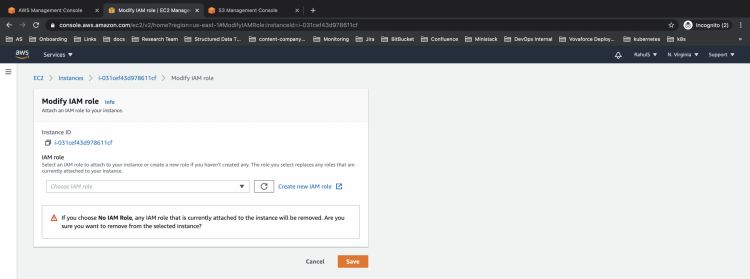
Confirma la operación.
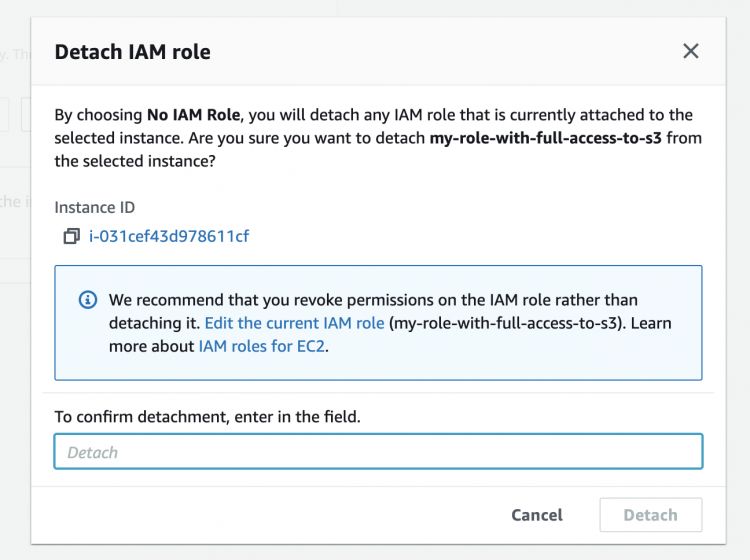
Esta vez si ejecutamos el comando «aws s3 ls», no podremos listar los buckets de la cuenta. No podremos realizar ninguna de las operaciones desde la Instancia EC2.

Conclusión
Así como gestionamos el bucket de AWS S3 desde la consola de AWS, también podemos gestionarlo desde la CLI. Hemos visto los pasos para instalar la utilidad de línea de comandos aws-cli. También vimos los pasos para conectar y desconectar el Rol I am de la instancia EC2. Realizamos algunas operaciones básicas en el bucket de S3 utilizando la utilidad de línea de comandos aws-cli.