Cómo instalar Apache Kafka en Ubuntu 22.04
Apache Kafka es un almacén de datos distribuido para procesar datos en streaming en tiempo real. Está desarrollado por Apache Software Foundation y escrito en Java y Scala. Apache Kafka se utiliza para construir canalizaciones de datos de flujo en tiempo real y aplicaciones que se adaptan al flujo de datos, especialmente para aplicaciones de nivel empresarial y aplicaciones de misión crítica. Es una de las plataformas de flujo de datos más populares, utilizada por miles de empresas para canalizaciones de datos de alto rendimiento, análisis de flujo e integración de datos.
Apache Kafka combina mensajería, almacenamiento y procesamiento de flujos en un solo lugar. Permite a los usuarios configurar flujos de datos potentes y de alto rendimiento para recopilar, procesar y transmitir datos en tiempo real. Se utiliza en aplicaciones distribuidas modernas con capacidad de escalado para manejar miles de millones de eventos en flujo.
En este tutorial, instalarás Apache Kafka en un servidor ubuntu 22.04. Aprenderás a instalar Apache Kafka manualmente a partir de paquetes binarios, lo que incluye la configuración básica para que Apache se ejecute como servicio y el funcionamiento básico utilizando Apache Kafka.
Requisitos previos
Para completar este tutorial, necesitarás los siguientes requisitos:
- Un servidor Ubuntu 22.04 con al menos 2GB o 4GB de memoria.
- Un usuario no root con privilegios de root/administrador.
Instalación de Java OpenJDK
Apache Kafka es un intermediario de procesamiento de flujos y mensajes escrito en Scala y Java. Para instalar Kafka, deberás instalar el Java OpenJDK en tu sistema Ubuntu En el momento de escribir esto, la última versión de Kafka v3.2 requería al menos el Java OpenJDK v11, que está disponible por defecto en el repositorio de Ubuntu.
Para empezar, ejecuta el siguiente comando apt para actualizar el repositorio de Ubuntu y refrescar el índice de paquetes.
sudo apt update
Instala el Java OpenJDK 11 utilizando el comando apt que aparece a continuación. Introduce Y para confirmar la instalación y pulsa ENTER, y comenzará la instalación.
sudo apt install default-jdk
El OpenJDK de Java ya está instalado en tu sistema Ubuntu. Utiliza el siguiente comando java para comprobar y verificar la versión de java. Verás que java OpenJDK v11 está instalado.
java version

Instalación de Apache Kafka
Después de instalar Java OpenJDK, iniciarás la instalación de Apache Kafka manualmente utilizando el paquete binario. En el momento de escribir esto, la última versión de Apache Kafka es la v3.2. Para instalarla, crearás un nuevo usuario del sistema y descargarás el paquete binario de Kafka.
Ejecuta el siguiente comando para crear un nuevo usuario del sistema llamado «kafka». Este usuario tendrá por defecto el directorio raíz «/opt/kafka» y deshabilitado el acceso al shell.
sudo useradd -r -d /opt/kafka -s /usr/sbin/nologin kafka
Descarga el paquete binario de Apache Kafka utilizando el siguiente comando curl. Deberías obtener el paquete de Apache Kafka «kafka_2.13-3.2.0.tgz».
sudo curl -fsSLo kafka.tgz https://dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.tgz
Una vez finalizada la descarga, extrae el archivo «kafka_2.13-3.2. 0.tgz» utilizando el comando tar. A continuación, mueve el directorio extraído a «/opt/kafka».
tar -xzf kafka.tgz sudo mv kafka_2.13-3.2.0 /opt/kafka
Ahora cambia la propiedad del directorio de instalación de Kafka«/opt/kafka» al usuario«kafka«.
sudo chown -R kafka:kafka /opt/kafka
A continuación, ejecuta el siguiente comando para crear un nuevo directorio«logs» para almacenar los archivos de registro de Apache kafka. A continuación, edita el archivo de configuración de Kafka«/opt/kafka/config/server.properties» utilizando el editor nano.
sudo -u kafka mkdir -p /opt/kafka/logs sudo -u kafka nano /opt/kafka/config/server.properties
Cambia la ubicación por defecto de los logs de Apache Kafka al directorio«/opt/kafka/logs«.
# logs configuration for Apache Kafka log.dirs=/opt/kafka/logs
Guarda y cierra el archivo cuando hayas terminado.
Configurar Apache Kafka como servicio
Llegados a este punto, ya tienes la configuración básica de Apache Kafka. Ahora, ¿cómo ejecutar Apache Kafka en tu sistema? La forma recomendada es ejecutar Apache Kafka como un servicio systemd. Esto te permite iniciar, detener y reiniciar Apache Kafka utilizando una única línea de comandos«systemctl«.
Para configurar el servicio Apache Kafka, primero tienes que configurar el servicio Zookeeper. El Apache Zookeeper se utiliza aquí para centralizar los servicios y mantener la elección del controlador, las configuraciones de los temas, las listas de control de acceso (ACL) y la pertenencia (para el clúster Kafka).
El Zookeeper se incluye por defecto en Apache Kafka. Configurarás el archivo de servicio para Zookeeper y, a continuación, crearás otro archivo de servicio para Kafka.
Ejecuta el siguiente comando para crear un nuevo archivo de servicio systemd «/etc/systemd/system/zookeeper.service» para Zookeeper.
sudo nano /etc/systemd/system/zookeeper.service Añade la siguiente configuración al archivo.
[Unit] Requires=network.target remote-fs.target After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Cuando hayas terminado, guarda y cierra el archivo.
A continuación, crea un nuevo archivo de servicio para Apache Kafka «/etc/systemd/system/kafka.service » utilizando el siguiente comando.
sudo nano /etc/systemd/system/kafka.service Añade la siguiente configuración al archivo. Este servicio Kafka sólo se ejecutará si está funcionando el servicio Zookeeper.
[Unit] Requires=zookeeper.service After=zookeeper.service [Service] Type=simple User=kafka ExecStart=/bin/sh -c '/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties > /opt/kafka/logs/start-kafka.log 2>&1' ExecStop=/opt/kafka/bin/kafka-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Guarda y cierra el archivo cuando hayas terminado.
Ahora recarga el gestor systemd utilizando el siguiente comando. Este comando aplicará los nuevos servicios systemd que acabas de crear.
sudo systemctl daemon-reload
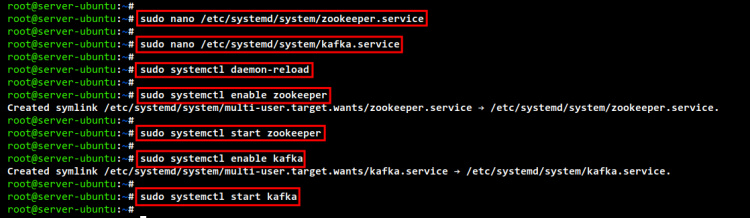
Ahora inicia y activa el servicio Zookeeper utilizando el siguiente comando.
sudo systemctl enable zookeeper sudo systemctl start zookeeper
A continuación, inicia y habilita el servicio Apache Kafka utilizando el siguiente comando.
sudo systemctl enable kafka sudo systemctl start kafka
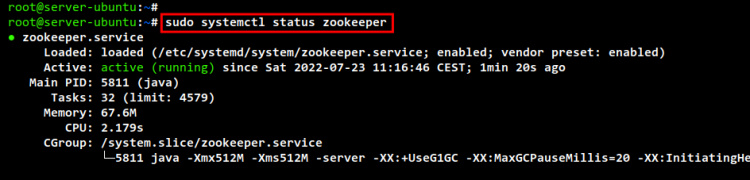
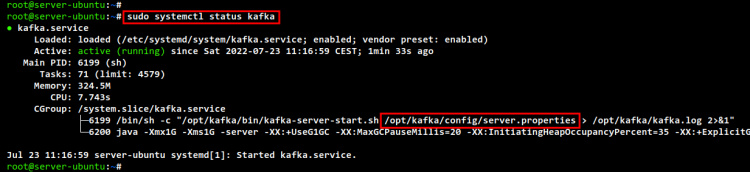
Por último, comprueba y verifica los servicios Zookeeper y Apache Kafka utilizando el comando siguiente.
sudo systemctl status zookeeper sudo systemctl status kafka
En la siguiente salida, puedes ver que el servicio Zookeeper está habilitado y se ejecutará automáticamente al iniciar el sistema. Y el estado actual del servicio Zookeeper es en ejecución.
El servicio Apache Kafka, también está activado y se ejecutará automáticamente al iniciarse el sistema. Y su estado actual es«en ejecución».
Funcionamiento básico de Apache Kafka
Has terminado la instalación básica de Apache Kafka, y ya se está ejecutando. Ahora aprenderás el funcionamiento básico de Apache Kafka desde la línea de comandos.
Todas las herramientas de línea de comandos de Apache Kafka están disponibles en el directorio«/opt/kafka/bin«.
Para crear un nuevo tema Kafka, utiliza el script«kafka-topics.sh» como se indica a continuación. En este ejemplo, estamos creando un nuevo tema Kafka con el nombre«TestTopic» con 1 replicación y partición. Y deberías obtener una salida como«Tema creado TestTopic».
sudo -u kafka /opt/kafka/bin/kafka-topics.sh \ --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic TestTopic
Para verificar las listas de temas disponibles en tu servidor Kafka, ejecuta el siguiente comando. Y deberías ver que el «TestTopic» que acabas de crear está disponible en el servidor Kafka.
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092

Ya has creado el tema Kafka, ahora puedes intentar escribir y hacer streaming de datos en Apache Kafka utilizando la línea de comandos estándar«kafka-console-producer.sh» y«kafka-console-consumer.sh«.
El script«kafka-console-producer.sh» es una utilidad de línea de comandos que puede utilizarse para escribir datos en el tema Kafka. Y el script «kafka-console-consumer.sh» se utiliza para transmitir datos desde el terminal.
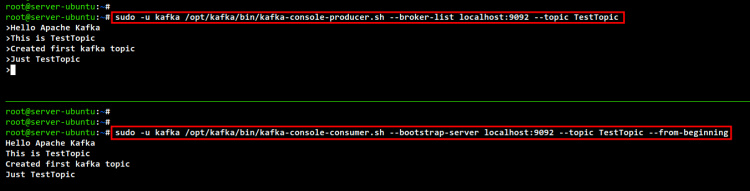
En la sesión de shell actual, ejecuta el siguiente comando para iniciar el Productor de Consola Kafka. Además, tendrás que especificar el tema Kafka para ello, en este ejemplo, utilizaremos el«TestTopic«.
sudo -u kafka /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TestTopic
A continuación, abre otra shell o terminal y conéctate al servidor Apache Kafka. A continuación, ejecuta el siguiente comando para iniciar el consumidor de Apache Kafka. Asegúrate de especificar aquí el tema Kafka.
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TestTopic --from-beginning
Ahora puedes escribir cualquier mensaje desde el Productor de la Consola Kafka y los mensajes aparecerán y se transmitirán automáticamente en el Consumidor de la Consola Kafka.
Ahora sólo tienes que pulsar«Ctrl+c» para salir del Productor y del Consumidor de la Consola Kafka.
Otra operación básica de Kafka que debes conocer aquí es cómo eliminar un tema en Kafka. Y esto también se puede hacer utilizando la utilidad de línea de comandos«kafka-topics.sh«.
Si quieres eliminar el tema «TestTopic«, puedes utilizar el siguiente comando. Ahora el tema «TestTopic» se eliminará de tu servidor Kafka.
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic TestTopic
Importar/Exportar tus datos como flujo utilizando el plugin Kafka Connect
Tienes que aprender el funcionamiento básico de Apache Kafka mediante la creación de temas, y el streaming de mensajes utilizando el Productor y el Consumidor de la Consola Kafka. Ahora aprenderás a transmitir mensajes desde un archivo mediante el plugin «Kafka Connect». Este plugin está disponible en la instalación por defecto de Kafka, los plugins por defecto para Kafka están disponibles en el directorio«/opt/kafka/libs«.
Edita el archivo de configuración«/opt/kafka/config/connect-standalone.properties» utilizando el editor nano.
sudo -u kafka nano /opt/kafka/config/connect-standalone.properties
Añade la siguiente configuración al archivo. Esto habilitará el plugin Kafka Connect que está disponible en el directorio «/opt/kafka/libs «.
plugin.path=libs/connect-file-3.2.0.jar
Cuando hayas terminado, guarda y cierra el archivo.
A continuación, crea un nuevo archivo de ejemplo que importarás y transmitirás a Kafka. Basándote en los archivos de configuración de Apache Kafka, debes crear el archivo«test.txt» en el directorio de instalación de Kafka«/opt/kafka«.
Ejecuta el siguiente comando para crear un nuevo archivo«/opt/kafka/test.txt».
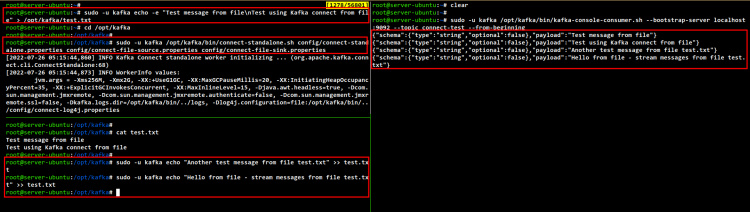
sudo -u kafka echo -e "Test message from file\nTest using Kafka connect from file" > /opt/kafka/test.txt
Desde el directorio de trabajo «/opt/kafka«, ejecuta el siguiente comando para iniciar el conector kafka en modo autónomo.
Además, aquí añadimos otros tres archivos de configuración como parámetros. Todos estos archivos contienen la configuración básica en la que se almacenarán los datos, en qué tema y qué archivo se procesará. El valor por defecto de estas configuraciones es que los datos estarán disponibles en el tema «conectar-prueba» con el archivo fuente «prueba.txt» que acabas de crear.
Verás muchos de los mensajes de salida de Kafka.
cd /opt/kafka sudo -u kafka /opt/kafka/bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
Ahora abre otra shell/sesión de terminal y ejecuta el siguiente comando para iniciar el consumidor de la consola Kafka. En este ejemplo, los flujos de datos estarán disponibles en el tema«conectar-prueba«.
Ahora verás que los datos del archivo«prueba.txt» se transmiten en tu shell actual del Consumidor de Consola.
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
Si intentas añadir otro mensaje al archivo «prueba.txt«, verás que el mensaje se transmitirá automáticamente en el Consumidor de Consola Kafka.
sudo -u kafka echo "Another test message from file test.txt" >> test.txt
Conclusión
En este tutorial, has aprendido a instalar Apache Kafka para el procesamiento de flujos y el intermediario de mensajes en el sistema Ubuntu 22.04. También has aprendido la configuración básica de Kafka en el sistema Ubuntu. Además, también has aprendido el funcionamiento básico utilizando el Productor y el Consumidor de Apache Kafka. Y al final, también has aprendido a transmitir mensajes o eventos desde un archivo a Apache Kafka.