Cómo configurar un cluster de Elasticsearch con 3 nodos en Ubuntu
Elasticsearch es una base de datos no-sql. Es el motor de búsqueda y análisis distribuido, de búsqueda y análisis en tiempo real para todo tipo de datos. Elasticsearch puede almacenar eficazmente cualquier tipo de datos, ya sean textos estructurados o no estructurados, datos numéricos, e indexarlos de forma que se puedan realizar búsquedas rápidas. Elasticsearch proporciona una sencilla API REST para gestionar el clúster e indexar/escribir y buscar los datos.
Elasticsearch está construido con Java e incluye una versión de OpenJDK.
Para entender Elasticsearch con más detalle, consulta su documentación oficial.
En este artículo, nos centraremos únicamente en cómo configurar un clúster de 3 nodos.
Requisitos previos
- Ubuntu 18.04 LTS
Qué vamos a hacer
- Descargar Elasticsearch
- Instalar Java 1.8
- Instalar y configurar Elasticsearch
- Probar el clúster
Descargar Elasticsearch
Para linux, la versión actual 7.4.2, a partir de ahora, de Elasticsearch puede descargarse utilizando el siguiente comando en tus sistemas linux.
Descarga en cada nodo (El nombre de la carpeta puede variar)
mkdir elastic1
cd elastic1/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-linux-x86_64.tar.gz
Si buscas una versión específica, siempre puedes navegar por los archivos en el sitio de Elasticsearch. Siempre es bueno ir con la última versión, ya que contiene todas las correcciones de los problemas de las versiones anteriores.

Instalar Java
Elasticsearch necesita que Java esté disponible en el sistema.
Para instalar OpenJDK 8, utiliza los siguientes comandos en tu servidor Ubuntu 18.04
En cada nodo
sudo apt update
sudo apt install openjdk-8-jdk
java --version
Instalar y configurar Elasticsearch
Ahora, es el momento de instalar Elasticsearch desde el archivo.
Extrae el paquete que acabamos de descargar en el paso anterior utilizando el siguiente comando.
Instala Elasticsearch en cada nodo
tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz
Configura Elasticsearch
Antes de iniciar el servicio, es necesario configurar Elasticsearch para que funcione en modo Cluster.
Aquí tenemos 3 servidores
es-nodo-1: 10.11.10.62 (Maestro inicial)
es-nodo-2: 10.11.14.248
es-nodo-3: 10.11.13.158
Abre el archivo config/elasticsearch.yml y añade lo siguiente en él. (Comprueba tus IPs)
vim config/elasticsearch.yml
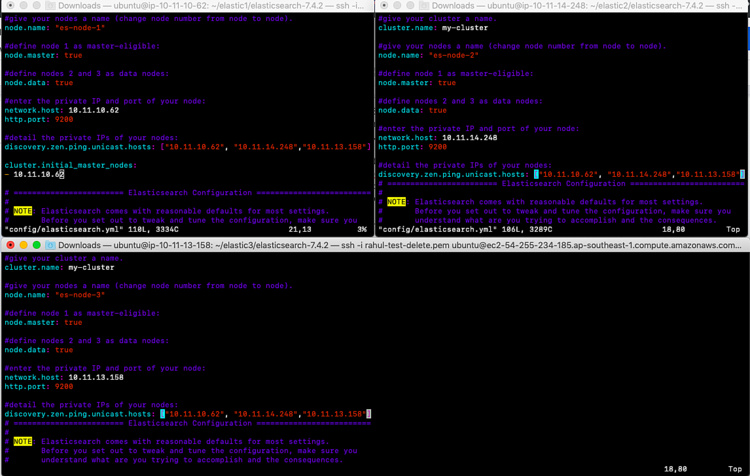
Añade en el maestro es-node-1 enconfig/elasticsearch.yml
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-1"
#define node 1 as master-eligible:
node.master: true
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.62
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.62", "10.11.14.248","10.11.13.158"]
cluster.initial_master_nodes:
- 10.11.10.62
Añadir On es-node-2 enconfig/elasticsearch .yml (Este nodo no contiene: cluster.initial_master_nodes)
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-2"
#define node 1 as master-eligible:
node.master: true
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.14.248
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.62", "10.11.14.248","10.11.13.158"]
Añade es-node-3 en config/elasticsearch.yml (Este nodo no contiene: cluster.initial_master_nodes)
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-3"
#define node 1 as master-eligible:
node.master: true
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.13.158
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.62", "10.11.14.248","10.11.13.158"]
Iniciar y probar el clúster
Inicia el clúster
En cada nodo (primero inicia el nodo maestro es-node1)
Utiliza el siguiente comando para iniciar Elasticsearch en primer plano
bin/elasticsearch
Nota:
Elasticsearch utiliza un mmapfs por defecto para almacenar sus índices. Es probable que los límites por defecto del sistema operativo en los recuentos de mmap sean demasiado bajos, lo que puede dar lugar a las siguientes excepciones de falta de memoria.
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
En Ubuntu 18.04 podemos podemos aumentar los límites ejecutando el siguiente comando como root/sudo:
sudo sysctl -w vm.max_map_count=262144
Añade -d a startpara iniciar Elasticsearch en segundo plano
bin/elasticsearch -d
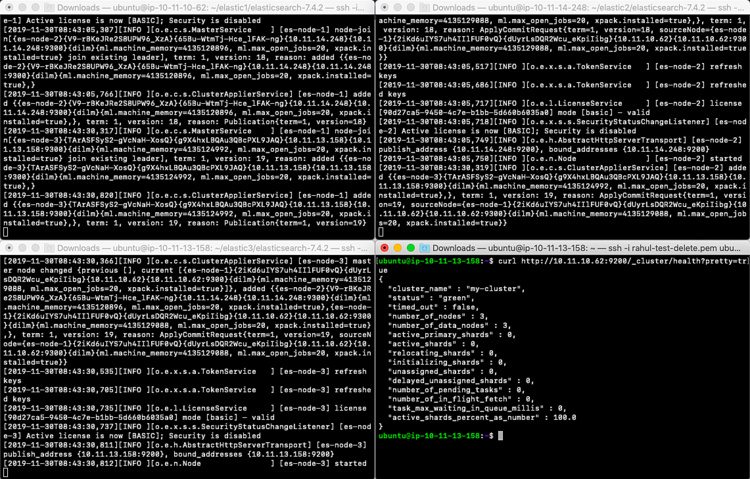
Una vez que se inicia el clúster, puedes ver los siguientes registros en es-nodo-1. Observa cómo los nodos se añaden a es-nodo-1 cuando se inician.
[2019-11-30T08:43:05,766][INFO ][o.e.c.s.ClusterApplierService] [es-node-1] added {{es-node-2}{V9-rBKeJRe2S8UPW96_XzA}{65Bu-WtmTj-Hce_lFAK-ng}{10.11.14.248}{10.11.14.248:9300}{dilm}{ml.machine_memory=4135120896, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 18, reason: Publication{term=1, version=18}
[2019-11-30T08:43:30,317][INFO ][o.e.c.s.MasterService ] [es-node-1] node-join[{es-node-3}{TArASFSyS2-gVcNaH-XosQ}{g9X4hxLBQAu3QBcPXL9JAQ}{10.11.13.158}{10.11.13.158:9300}{dilm}{ml.machine_memory=4135124992, ml.max_open_jobs=20, xpack.installed=true} join existing leader], term: 1, version: 19, reason: added {{es-node-3}{TArASFSyS2-gVcNaH-XosQ}{g9X4hxLBQAu3QBcPXL9JAQ}{10.11.13.158}{10.11.13.158:9300}{dilm}{ml.machine_memory=4135124992, ml.max_open_jobs=20, xpack.installed=true},}
[2019-11-30T08:43:30,820][INFO ][o.e.c.s.ClusterApplierService] [es-node-1] added {{es-node-3}{TArASFSyS2-gVcNaH-XosQ}{g9X4hxLBQAu3QBcPXL9JAQ}{10.11.13.158}{10.11.13.158:9300}{dilm}{ml.machine_memory=4135124992, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 19, reason: Publication{term=1, version=19
Prueba el clúster
Abre un nuevo terminal desde el que se pueda acceder al clúster y prueba los siguientes comandos
curl http://10.11.10.62:9200/_cluster/stats?pretty

curl http://10.11.10.62:9200/_nodes/process?pretty

curl http://10.11.10.62:9200/_cluster/stats?pretty

Conclusión
En este artículo hemos visto los pasos para descargar la última versión de elasticsearch, instalar Java 8, configurar Elasticsearch, iniciar y probar el clúster.