Cómo instalar Apache Spark en Ubuntu 22.04
Apache Spark es un motor de procesamiento de datos gratuito, de código abierto y de uso general, utilizado por los científicos de datos para realizar consultas de datos extremadamente rápidas sobre una gran cantidad de datos. Utiliza un almacén de datos en memoria para almacenar las consultas y los datos directamente en la memoria principal de los nodos del clúster. Ofrece API de alto nivel en los lenguajes Java, Scala, Python y R. También es compatible con un rico conjunto de herramientas de nivel superior, como Spark SQL, MLlib, GraphX y Spark Streaming.
Este post te mostrará cómo instalar el motor de procesamiento de datos Apache Spark en Ubuntu 22.04.
Requisitos previos
- Un servidor que ejecute Ubuntu 22.04.
- Una contraseña de root configurada en el servidor.
Instalar Java
Apache Spark se basa en Java. Por tanto, Java debe estar instalado en tu servidor. Si no está instalado, puedes instalarlo ejecutando el siguiente comando:
apt-get install default-jdk curl -y
Una vez instalado Java, verifica la instalación de Java mediante el siguiente comando:
java -version
Obtendrás la siguiente salida:
openjdk version "11.0.15" 2022-04-19 OpenJDK Runtime Environment (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1) OpenJDK 64-Bit Server VM (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1, mixed mode, sharing)
Instalar Apache Spark
En el momento de escribir este tutorial, la última versión de Apache Spark es Spark 3.2.1. Puedes descargarla utilizando el comando wget:
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
Una vez finalizada la descarga, extrae el archivo descargado utilizando el siguiente comando:
tar xvf spark-3.2.1-bin-hadoop3.2.tgz
A continuación, extrae el fiel descargado al directorio /opt:
mv spark-3.2.1-bin-hadoop3.2/ /opt/spark
A continuación, edita el archivo .bashrc y define la ruta del Apache Spark:
nano ~/.bashrc
Añade las siguientes líneas al final del archivo:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Guarda y cierra el archivo y, a continuación, activa la variable de entorno Spark mediante el siguiente comando:
source ~/.bashrc
A continuación, crea un usuario dedicado para ejecutar Apache Spark:
useradd spark
A continuación, cambia la propiedad de /opt/spark al usuario y grupo spark:
chown -R spark:spark /opt/spark
Crear un archivo de servicio Systemd para Apache Spark
A continuación, tendrás que crear un archivo de servicio para gestionar el servicio Apache Spark.
En primer lugar, crea un archivo de servicio para el maestro Spark utilizando el siguiente comando:
nano /etc/systemd/system/spark-master.service
Añade las siguientes líneas:
[Unit] Description=Apache Spark Master After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-master.sh ExecStop=/opt/spark/sbin/stop-master.sh [Install] WantedBy=multi-user.target
Guarda y cierra el archivo y, a continuación, crea un archivo de servicio para Spark slave:
nano /etc/systemd/system/spark-slave.service
Añade las siguientes líneas:
[Unit] Description=Apache Spark Slave After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-slave.sh spark://your-server-ip:7077 ExecStop=/opt/spark/sbin/stop-slave.sh [Install] WantedBy=multi-user.target
Guarda y cierra el archivo y vuelve a cargar el demonio systemd para aplicar los cambios:
systemctl daemon-reload
A continuación, inicia y habilita el servicio maestro de Spark mediante el siguiente comando:
systemctl start spark-master systemctl enable spark-master
Puedes comprobar el estado del Spark master utilizando el siguiente comando:
systemctl status spark-master
Obtendrás la siguiente salida:
? spark-master.service - Apache Spark Master
Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:48:15 UTC; 2s ago
Process: 19924 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS)
Main PID: 19934 (java)
Tasks: 32 (limit: 4630)
Memory: 162.8M
CPU: 6.264s
CGroup: /system.slice/spark-master.service
??19934 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.mast>
May 05 11:48:12 ubuntu2204 systemd[1]: Starting Apache Spark Master...
May 05 11:48:12 ubuntu2204 start-master.sh[19929]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org>
May 05 11:48:15 ubuntu2204 systemd[1]: Started Apache Spark Master.
Cuando hayas terminado, puedes pasar al siguiente paso.
Accede a Apache Spark
En este punto, Apache Spark está iniciado y escuchando en el puerto 8080. Puedes comprobarlo con el siguiente comando:
ss -antpl | grep java
Obtendrás la siguiente salida:
LISTEN 0 4096 [::ffff:69.28.88.159]:7077 *:* users:(("java",pid=19934,fd=256))
LISTEN 0 1 *:8080 *:* users:(("java",pid=19934,fd=258))
Ahora, abre tu navegador web y accede a la interfaz web de Spark utilizando la URL http://your-server-ip:8080. Deberías ver el panel de control de Apache Spark en la siguiente página:
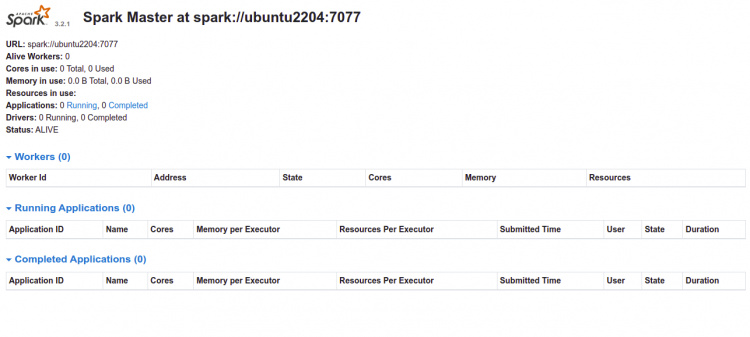
Ahora, inicia el servicio esclavo Spark y habilítalo para que se inicie al reiniciar el sistema:
systemctl start spark-slave systemctl enable spark-slave
Puedes comprobar el estado del servicio esclavo Spark utilizando el siguiente comando:
systemctl status spark-slave
Obtendrás la siguiente salida:
? spark-slave.service - Apache Spark Slave
Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:49:32 UTC; 4s ago
Process: 20006 ExecStart=/opt/spark/sbin/start-slave.sh spark://69.28.88.159:7077 (code=exited, status=0/SUCCESS)
Main PID: 20017 (java)
Tasks: 35 (limit: 4630)
Memory: 185.9M
CPU: 7.513s
CGroup: /system.slice/spark-slave.service
??20017 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.work>
May 05 11:49:29 ubuntu2204 systemd[1]: Starting Apache Spark Slave...
May 05 11:49:29 ubuntu2204 start-slave.sh[20006]: This script is deprecated, use start-worker.sh
May 05 11:49:29 ubuntu2204 start-slave.sh[20012]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spark-org.>
May 05 11:49:32 ubuntu2204 systemd[1]: Started Apache Spark Slave.
Ahora, vuelve a la interfaz web de Spark y actualiza la página web. Deberías ver el Trabajador añadido en la siguiente página:
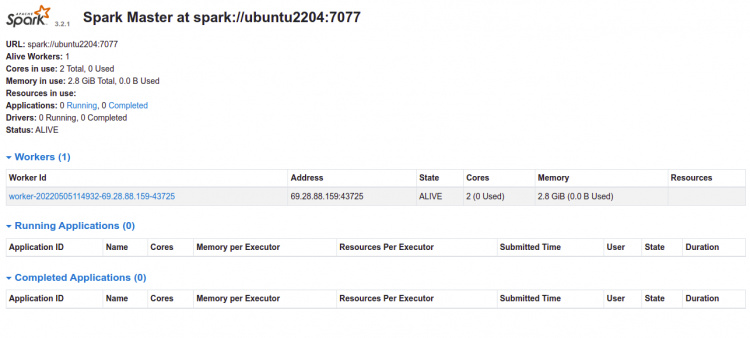
Ahora, haz clic en el trabajador. Deberías ver la información del trabajador en la siguiente página:
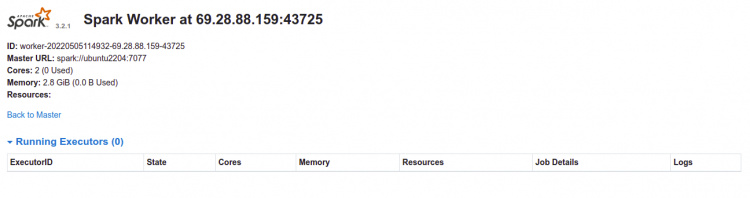
Cómo acceder a Spark Shell
Apache Spark también proporciona una utilidad spark-shell para acceder a Spark a través de la línea de comandos. Puedes acceder a ella con el siguiente comando:
spark-shell
Obtendrás la siguiente salida:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:50:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751448361).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.15)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Para salir de la Spark shell, ejecuta el siguiente comando:
scala> :quit
Si eres desarrollador de Python, utiliza pyspark para acceder a Spark:
pyspark
Obtendrás la siguiente salida:
Python 3.10.4 (main, Apr 2 2022, 09:04:19) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:53:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Python version 3.10.4 (main, Apr 2 2022 09:04:19)
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751598729).
SparkSession available as 'spark'.
>>>
Pulsa la tecla CTRL + D para salir del intérprete de comandos Spark.
Conclusión
Enhorabuena! has instalado correctamente Apache Spark en Ubuntu 22.04. Ahora puedes empezar a utilizar Apache Spark en el entorno Hadoop. Para más información, lee la página de documentación de Apache Spark.