Cómo instalar TIG Stack (Telegraf, InfluxDB y Grafana) en Ubuntu 22.04
La pila TIG (Telegraf, InfluxDB y Grafana) es el acrónimo de una plataforma de herramientas de código abierto para facilitar la recopilación, almacenamiento, representación gráfica y alerta de las métricas del sistema. Puedes supervisar y visualizar métricas como la memoria, el espacio en disco, los usuarios registrados, la carga del sistema, el uso de swap, el tiempo de actividad, los procesos en ejecución, etc. desde un solo lugar. Las herramientas utilizadas en la pila son las siguientes:
- Telegraf – es un agente de recopilación de métricas de código abierto para recoger y enviar datos y eventos de bases de datos, sistemas y sensores IoT. Admite varios plugins de salida, como InfluxDB, Graphite, Kafka, etc., a los que puede enviar los datos recopilados.
- InfluxDB – es una base de datos de series temporales de código abierto escrita en lenguaje Go. Está optimizada para un almacenamiento rápido y de alta disponibilidad, y es adecuada para todo lo que implique grandes cantidades de datos con marcas temporales, como métricas, eventos y análisis en tiempo real.
- Grafana – es una suite de visualización y monitorización de datos de código abierto. Admite varios plugins de entrada, como Graphite, ElasticSearch, InfluxDB, etc. Proporciona un bonito panel de control y análisis de métricas que te permite visualizar y supervisar cualquier tipo de métricas del sistema y datos de rendimiento.
En este tutorial, aprenderás a instalar y configurar TIG Stack en un único servidor Ubuntu 22.04.
Requisitos previos
- Un servidor con Ubuntu 22.04.
- Un usuario no usuario con privilegios de root.
- El Cortafuegos sin complicaciones(UFW) está activado y en ejecución.
- Asegúrate de que todo está actualizado.
$ sudo apt update && sudo apt upgrade
Paso 1 – Configurar el Cortafuegos
Antes de instalar ningún paquete, el primer paso es configurar el cortafuegos para que abra puertos para InfluxDB y Grafana.
Comprueba el estado del cortafuegos.
$ sudo ufw status
Deberías ver algo como lo siguiente
Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6)
Abre el puerto 8086 para InfluxDB y el 3000 para el servidor Grafana.
$ sudo ufw allow 8086 $ sudo ufw allow 3000
Vuelve a comprobar el estado para confirmarlo.
$ sudo ufw status Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere 8086 ALLOW Anywhere 3000 ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6) 8086 (v6) ALLOW Anywhere (v6) 3000 (v6) ALLOW Anywhere (v6)
Paso 2 – Instalar InfluxDB
Utilizaremos el repositorio oficial de InfluxDB para instalarlo.
Descarga la clave GPG de InfluxDB.
$ wget -q https://repos.influxdata.com/influxdb.key
Importa la clave GPG al servidor.
$ echo '23a1c8836f0afc5ed24e0486339d7cc8f6790b83886c4c96995b88a061c5bb5d influxdb.key' | sha256sum -c && cat influxdb.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/influxdb.gpg > /dev/null
Importa el repositorio de InfluxDB.
$ echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdb.gpg] https://repos.influxdata.com/debian stable main' | sudo tee /etc/apt/sources.list.d/influxdata.list
Actualiza la lista de repositorios del sistema.
$ sudo apt update
Tienes la opción de instalar InfluxDB 1.8.x o 2.0.x. Sin embargo, es mejor utilizar la última versión. Instala InfluxDB.
$ sudo apt install influxdb2
Inicia el servicio InfluxDB.
$ sudo systemctl start influxdb
Comprueba el estado del servicio.
$ sudo systemctl status influxdb
? influxdb.service - InfluxDB is an open-source, distributed, time series database
Loaded: loaded (/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-09-13 00:00:27 UTC; 42s ago
Docs: https://docs.influxdata.com/influxdb/
Process: 12514 ExecStart=/usr/lib/influxdb/scripts/influxd-systemd-start.sh (code=exited, status=0/SUCCESS)
Main PID: 12515 (influxd)
Tasks: 7 (limit: 1030)
Memory: 48.5M
CPU: 547ms
CGroup: /system.slice/influxdb.service
??12515 /usr/bin/influxd
........
Paso 3 – Crear la base de datos InfluxDB y las credenciales de usuario
Para almacenar los datos de Telegraf, necesitas configurar la base de datos y el usuario de Influx.
InfluxDB viene con una herramienta de línea de comandos llamada influx para interactuar con el servidor InfluxDB. Piensa en influx como la herramienta de línea de comandos mysql.
Ejecuta el siguiente comando para realizar la configuración inicial de Influx.
$ influx setup > Welcome to InfluxDB 2.0! ? Please type your primary username navjot ? Please type your password *************** ? Please type your password again *************** ? Please type your primary organization name howtoforge ? Please type your primary bucket name tigstack ? Please type your retention period in hours, or 0 for infinite 360 ? Setup with these parameters? Username: navjot Organization: howtoforge Bucket: tigstack Retention Period: 360h0m0s Yes User Organization Bucket navjot howtoforge tigstack
Necesitas configurar tu nombre de usuario inicial, tu contraseña, el nombre de la organización, el nombre del bucket primario para almacenar datos y el periodo de retención en horas para esos datos. Tus datos se almacenan en el archivo /home/username/.influxdbv2/configs.
También puedes realizar esta configuración iniciando la URL http://<serverIP>:8086/ en tu navegador. Una vez que hayas realizado la configuración inicial, puedes iniciar sesión en la URL con las credenciales creadas anteriormente.

Aparecerá el siguiente panel de control.
El proceso de configuración inicial crea un token por defecto que tiene acceso total de lectura y escritura a todas las organizaciones de la base de datos. Necesitarás un nuevo token por motivos de seguridad, que sólo se conectará a la organización y al cubo a los que queremos conectarnos.
Para crear un nuevo token, haz clic en el siguiente icono de la barra lateral izquierda y haz clic en el enlace Tokens de API para continuar.
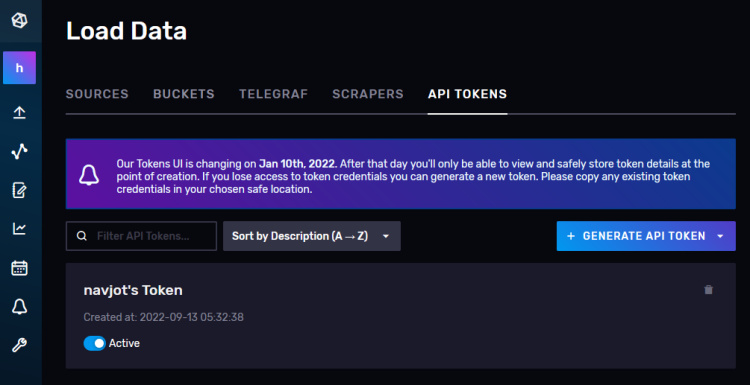
Accederás a la página Tokens de la API. Aquí verás el token por defecto que creamos en el momento de la configuración inicial.
Haz clic en el botón Generar Tok en y selecciona la opción Token de Lectura/Escritura para lanzar una nueva ventana emergente superpuesta. Dale un nombre al Token (telegraf) y selecciona el cubo por defecto que creamos en las secciones de Lectura y Escritura.
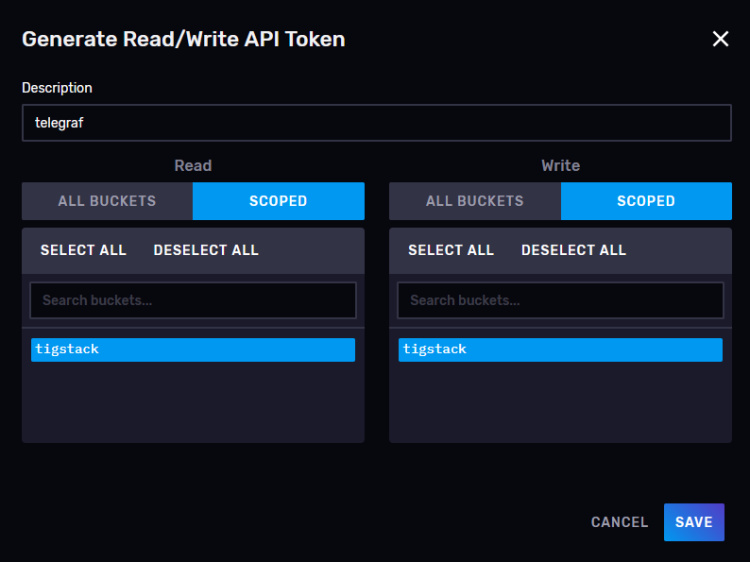
Haz clic en Guardar para terminar de crear el token. Haz clic en el nombre del token recién creado para que aparezca una ventana emergente con el valor del token.
Guárdalo por ahora, ya que lo necesitaremos más adelante.
Esto completa la instalación y configuración de InfluxDB. A continuación, tenemos que instalar Telegraf.
Paso 4 – Instalar Telegraf
Telegraf e InfluxDB comparten el mismo repositorio. Esto significa que puedes instalar Telegraf directamente.
$ sudo apt install telegraf
El servicio de Telegraf se activa e inicia automáticamente durante la instalación.
Telegraf es un agente basado en plugins y tiene 4 tipos de plugins:
- Los plugins deentrada recogen métricas.
- Los pluginsprocesadores transforman, decoran y filtran las métricas.
- Los pluginsagregadores crean y agregan métricas.
- Los plugins desalida definen los destinos a los que se envían las métricas, incluido InfluxDB.
Telegraf almacena la configuración de todos estos plugins en el archivo /etc/telegraf/telegraf.conf. El primer paso es conectar Telegraf a InfluxDB activando el plugin de salida influxdb_v2. Abre el archivo /etc/telegraf/telegraf.conf para editarlo.
$ sudo nano /etc/telegraf/telegraf.conf
Busca la línea [[outputs.influxdb_v2]] y descoméntala eliminando el # que hay delante. Edita el código que hay debajo de la siguiente manera.
# # Configuration for sending metrics to InfluxDB 2.0 [[outputs.influxdb_v2]] # ## The URLs of the InfluxDB cluster nodes. # ## # ## Multiple URLs can be specified for a single cluster, only ONE of the # ## urls will be written to each interval. # ## ex: urls = ["https://us-west-2-1.aws.cloud2.influxdata.com"] urls = ["http://127.0.0.1:8086"] # # ## Token for authentication. token = "$INFLUX_TOKEN" # # ## Organization is the name of the organization you wish to write to. organization = "howtoforge" # # ## Destination bucket to write into. bucket = "tigstack"
Pega el valor del token InfluxDB guardado anteriormente en lugar de la variable $INFLUX_TOKEN en el código anterior.
Busca la línea INPUT PLUGINS y verás los siguientes plugins de entrada activados por defecto.
# Read metrics about cpu usage [[inputs.cpu]] ## Whether to report per-cpu stats or not percpu = true ## Whether to report total system cpu stats or not totalcpu = true ## If true, collect raw CPU time metrics collect_cpu_time = false ## If true, compute and report the sum of all non-idle CPU states report_active = false ## If true and the info is available then add core_id and physical_id tags core_tags = false # Read metrics about disk usage by mount point [[inputs.disk]] ## By default stats will be gathered for all mount points. ## Set mount_points will restrict the stats to only the specified mount points. # mount_points = ["/"] ## Ignore mount points by filesystem type. ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"] ## Ignore mount points by mount options. ## The 'mount' command reports options of all mounts in parathesis. ## Bind mounts can be ignored with the special 'bind' option. # ignore_mount_opts = [] # Read metrics about disk IO by device [[inputs.diskio]] .... .... # Get kernel statistics from /proc/stat [[inputs.kernel]] # no configuration # Read metrics about memory usage [[inputs.mem]] # no configuration # Get the number of processes and group them by status [[inputs.processes]] # no configuration # Read metrics about swap memory usage [[inputs.swap]] # no configuration # Read metrics about system load & uptime [[inputs.system]] # no configuration
Puedes configurar plugins de entrada adicionales en función de tus necesidades, como Apache Server, contenedores Docker, Elasticsearch, cortafuegos iptables, Kubernetes, Memcached, MongoDB, MySQL, Nginx, PHP-fpm, Postfix, RabbitMQ, Redis, Varnish, Wireguard, PostgreSQL, etc.
Cuando hayas terminado, guarda el archivo pulsando Ctrl + X e introduciendo Y cuando te lo pida.
Reinicia el servicio Telegraf cuando hayas terminado de aplicar los cambios.
$ sudo systemctl restart telegraf
Paso 5 – Comprueba si las estadísticas de Telegraf se almacenan en InfluxDB
Antes de seguir adelante, tienes que verificar si las estadísticas de Telegraf se recogen correctamente y se introducen en InfluxDB. Abre la IU de InfluxDB en tu navegador y haz clic en el tercer icono de la barra lateral izquierda y selecciona el menú Cubos.
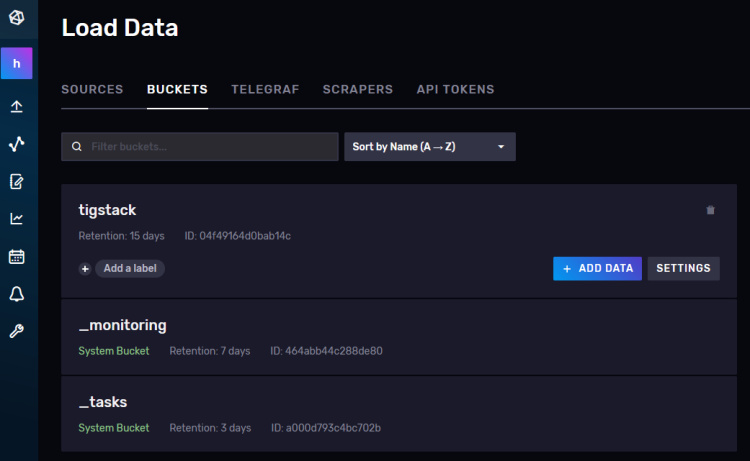
Haz clic en tigstack y aparecerá la siguiente página.
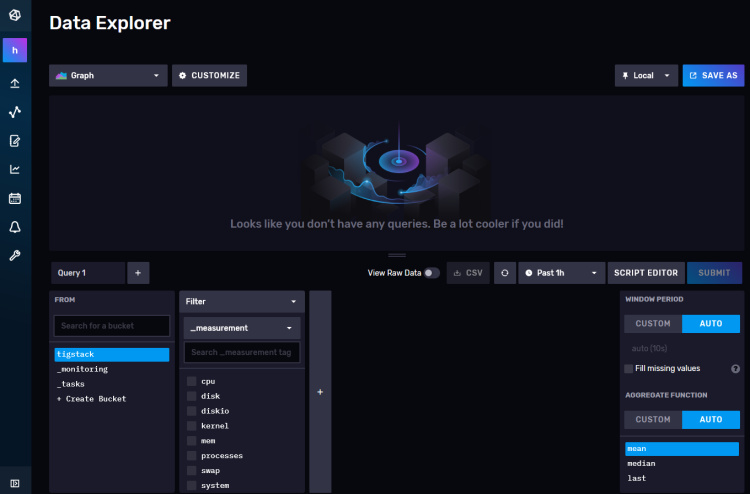
Haz clic en el nombre del cubo y, a continuación, en uno de los valores del filtro _measurement, y sigue haciendo clic en otros valores a medida que aparezcan. Cuando hayas terminado, pulsa el botón Enviar. Deberías ver un gráfico en la parte superior. Puede que tengas que esperar algún tiempo hasta que aparezcan los datos.
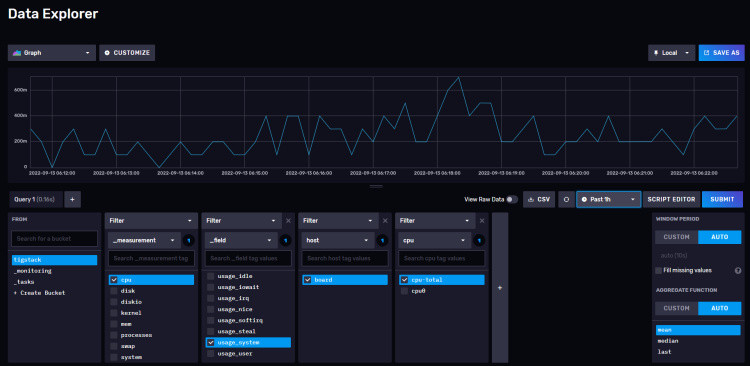
Esto debería confirmar que los datos se están transmitiendo correctamente.
Paso 6 – Instalar Grafana
Utilizaremos el repositorio oficial de Grafana para instalarlo. Importa la clave GPG de Grafana.
$ sudo wget -q -O /usr/share/keyrings/grafana.key https://packages.grafana.com/gpg.key
Añade el repositorio a tu sistema.
$ echo "deb [signed-by=/usr/share/keyrings/grafana.key] https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
Actualiza la lista de repositorios del sistema.
$ sudo apt update
Instala Grafana.
$ sudo apt install grafana
Inicia y habilita el servicio Grafana.
$ sudo systemctl enable grafana-server --now
Comprueba el estado del servicio.
$ sudo systemctl status grafana-server
? grafana-server.service - Grafana instance
Loaded: loaded (/lib/systemd/system/grafana-server.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-09-13 01:04:47 UTC; 2s ago
Docs: http://docs.grafana.org
Main PID: 13674 (grafana-server)
Tasks: 7 (limit: 1030)
Memory: 104.6M
CPU: 1.050s
CGroup: /system.slice/grafana-server.service
??13674 /usr/sbin/grafana-server --config=/etc/grafana/grafana.ini --pidfile=/run/grafana/grafana-server.pid --packaging=deb cfg:default.paths.logs=/var/log/grafana
.......
Paso 7 – Configurar la fuente de datos de Grafana
Inicia la URL http://<serverIP>:3000 en tu navegador y la siguiente página de inicio de sesión de Grafana debería darte la bienvenida.
Inicia sesión con el nombre de usuario predeterminado admin y la contraseña admin. A continuación, debes configurar una nueva contraseña por defecto.
Te aparecerá la siguiente página de inicio de Grafana. Haz clic en el botón Añade tu primera fuente de datos.
Haz clic en el botón InfluxDB.
En la página siguiente, selecciona Flux en el menú desplegable como lenguaje de consulta. Puedes utilizar InfluxQL como lenguaje de consulta, pero es más complicado de configurar ya que sólo admite InfluxDB v1.x por defecto. Flux es compatible con InfluxDB v2.x y es más fácil de instalar y configurar.
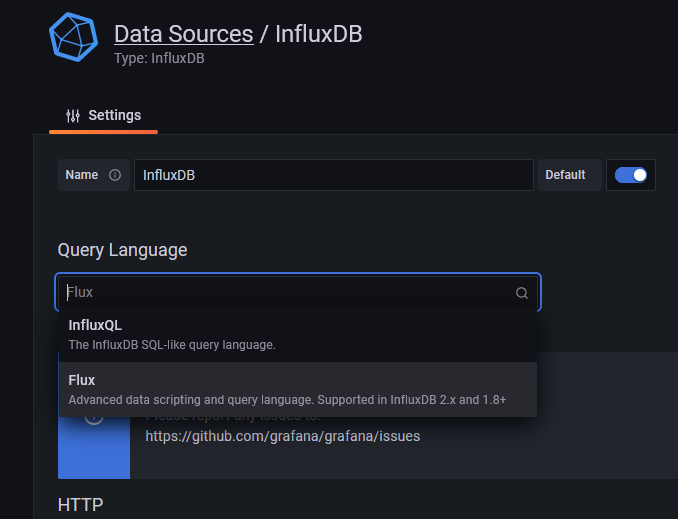
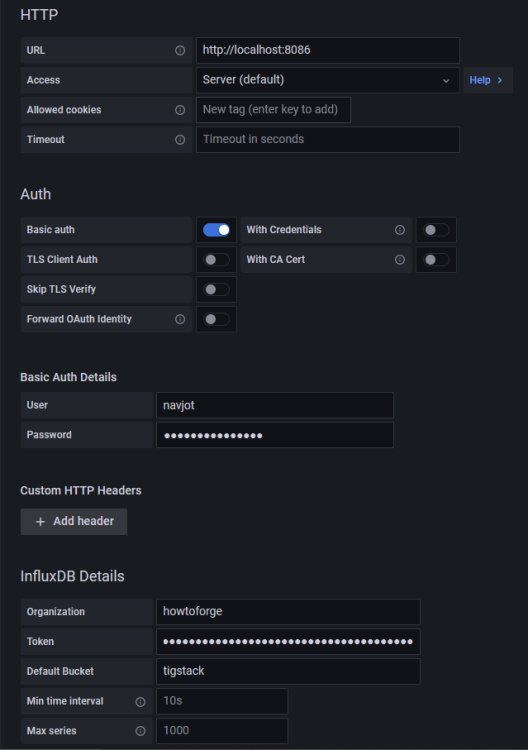
Introduce los siguientes valores.
URL: http://localhost:8086
Acceso: Servidor
Datos básicos de autenticación
Usuario: navjot
Contraseña <yourinfluxdbpassword>
Detalles de InfluxDB
Organización: howtoforge
Token: <influxdbtoken>
Bucket por defecto: tigstack
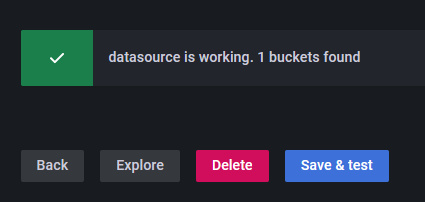
Haz clic en el botón Guardar y probar y deberías ver un mensaje de confirmación verificando que la configuración se ha realizado correctamente.
Paso 8 – Configurar los Cuadros de Mando de Grafana
El siguiente paso es configurar los Cuadros de mando de Grafana. Haz clic en el signo con los cuatro cuadrados y selecciona Cuadros de mando para abrir la pantalla Crear Cuadro de mando.
En la página siguiente, haz clic en el botón Añadir un nuevo panel para abrir la siguiente pantalla.
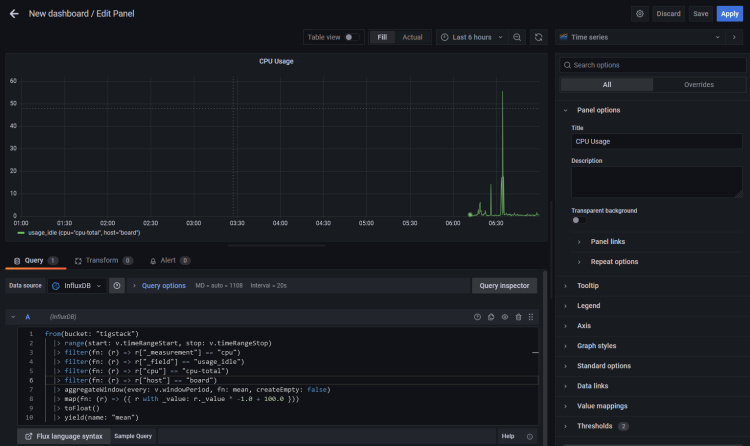
Pega el siguiente código en el Editor de consultas. Este
from(bucket: "NAMEOFYOUBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_idle")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({ r with _value: r._value * -1.0 + 100.0 }))
|> toFloat()
|> yield(name: "mean")
Utiliza el nombre del cubo que hemos utilizado anteriormente. Y el nombre del host que puedes recuperar del archivo /etc/hostname.
El código anterior calculará el Uso de la CPU y generará un gráfico para ello. Dale un Título al Panel.
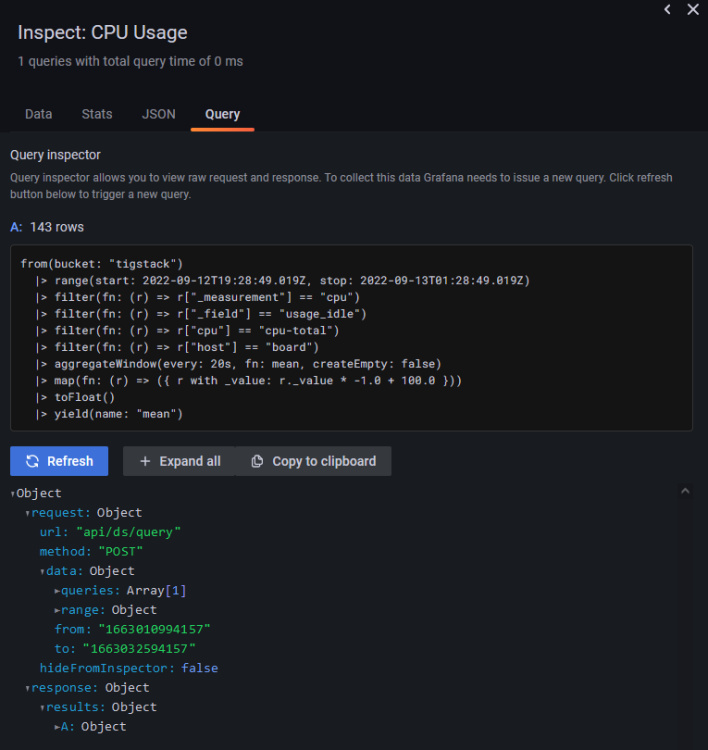
Haz clic en el botón Inspector de consultas y luego en el botón Actualizar para comprobar si tu consulta funciona correctamente. Haz clic en el icono de la cruz para cerrar el inspector.
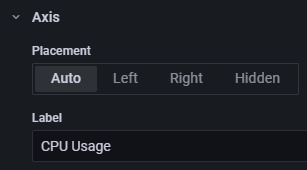
También puedes dar un nombre al eje utilizando el campo Etiqueta de la derecha, debajo de la sección Eje.
Pulsa el botón Aplicar para guardar el panel.
Pulsa el botón Guardar Cuadro de Mando, una vez hayas terminado.
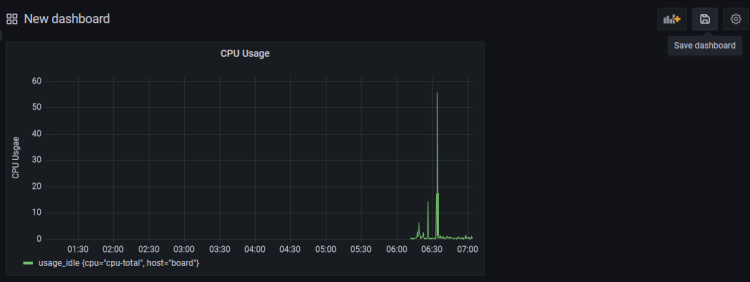
Dale un nombre al panel de control y haz clic en Guardar para terminar.
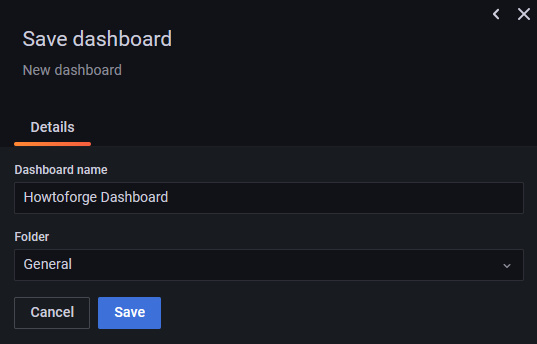
Se abrirá el panel de control y haz clic en el botón Añadir Panel para crear otro panel.
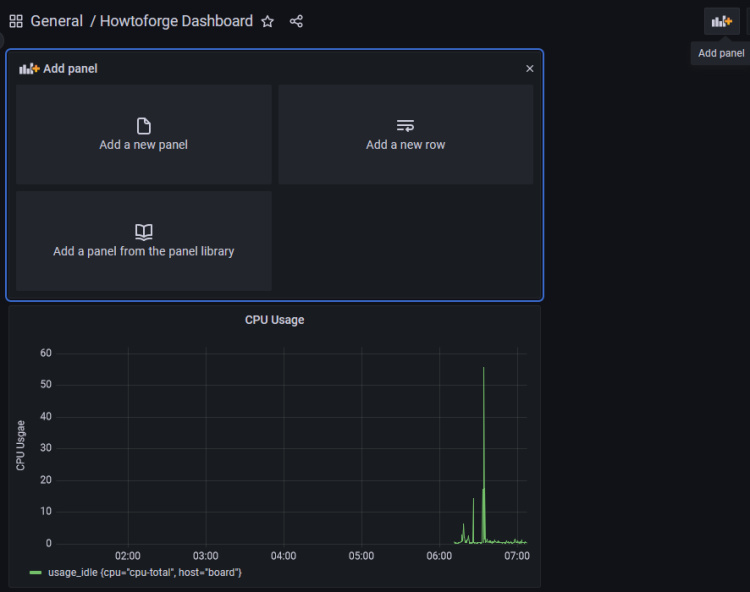
Repite el proceso creando otro panel para el Uso de RAM.
from(bucket: "NAMEOFYOUBUCKET") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "mem") |> filter(fn: (r) => r["_field"] == "used_percent") |> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST") |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false) |> yield(name: "mean")
Y utiliza el siguiente código para mostrar el Uso del Disco Duro.
from(bucket: "NAMEOFYOURBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "disk")
|> filter(fn: (r) => r["_field"] == "used")
|> filter(fn: (r) => r["path"] == "/")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({ r with _value: r._value / 1000000.0 }))
|> toFloat()
|> yield(name: "mean")
Puedes crear un número ilimitado de paneles.
El código anterior se basa en el lenguaje Flux Scripting. Afortunadamente, no necesitas aprender el lenguaje para escribir consultas. Puedes generar la consulta a partir de la URL de InfluxDB. Aunque aprender el lenguaje puede beneficiarte en la optimización de las consultas.
Tienes que volver al panel de InfluxDB y abrir la página Explorar para obtener la consulta.
Haz clic en el nombre del cubo y, a continuación, en uno de los valores del filtro _measurement, y sigue haciendo clic en otros valores a medida que aparezcan. Cuando hayas terminado, haz clic en el botón Editor de Script y deberías ver la página siguiente. El gráfico también debería actualizarse.
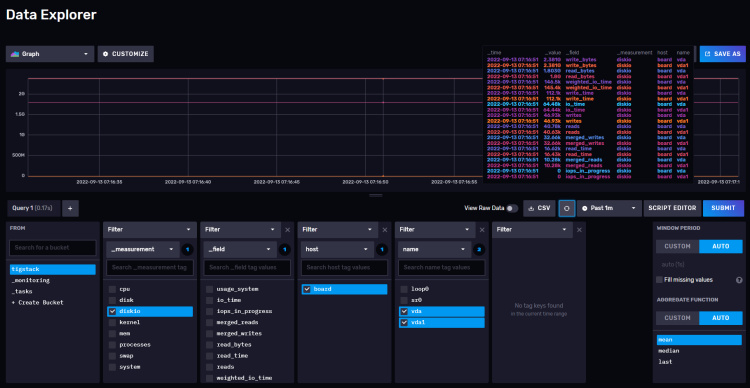
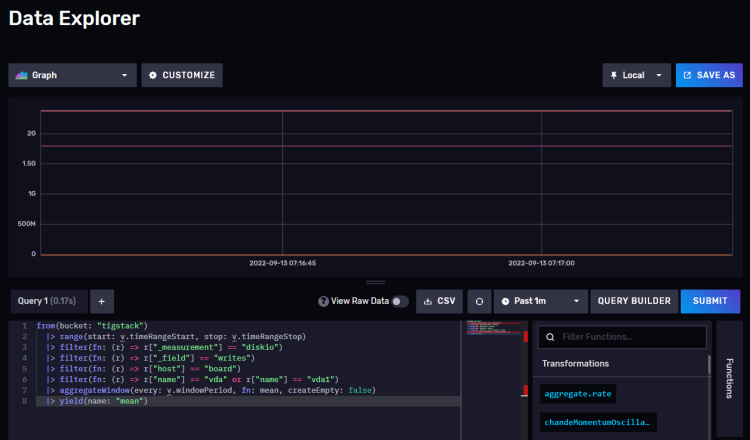
Copia la consulta mostrada y ya podrás utilizarla en el panel de control de Grafana para construir tus gráficos.
Paso 9 – Configurar alertas y notificaciones
El uso principal de configurar monitores es recibir alertas puntuales cuando el valor supera un determinado umbral.
El primer paso es establecer el destino donde quieres recibir las alertas. Puedes recibir notificaciones por correo electrónico, Slack, Kafka, Google Hangouts Chat, Microsoft Teams, Telegram, etc.
Para nuestro tutorial habilitaremos las notificaciones por correo electrónico. Para configurar las notificaciones por correo electrónico, primero tenemos que configurar el servicio SMTP. Abre el archivo /etc/grafana/grafana.ini para configurar el SMTP.
$ sudo nano /etc/grafana/grafana.ini
Busca en él la siguiente línea [smtp]. Descomenta las siguientes líneas e introduce los valores para el servidor SMTP personalizado.
[smtp] enabled = true host = email-smtp.us-west-2.amazonaws.com:587 user = YOURUSERNAME # If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;""" password = YOURUSERPASSWORD ;cert_file = ;key_file = ;skip_verify = false from_address = [email protected] from_name = HowtoForge Grafana # EHLO identity in SMTP dialog (defaults to instance_name) ;ehlo_identity = dashboard.example.com # SMTP startTLS policy (defaults to 'OpportunisticStartTLS') ;startTLS_policy = NoStartTLS
Guarda el archivo pulsando Ctrl + X e introduciendo Y cuando se te solicite.
Reinicia el servidor Grafana para aplicar la configuración.
$ sudo systemctl restart grafana-server
Abre la página de Grafana y haz clic en el icono Alerta y en Puntos de contacto.
Grafana crea y configura automáticamente un punto de contacto de correo electrónico predeterminado que debe configurarse con la dirección de correo electrónico correcta. Haz clic en el botón de edición del punto de contacto grafana-default-email.
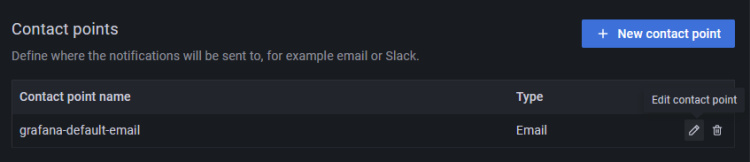
Introduce los detalles para configurar el canal de notificación por correo electrónico.
Si quieres enviar un mensaje adicional, haz clic en el enlace Configuración de correo electrónico opcional e introduce el mensaje.
Haz clic en Probar para comprobar si la configuración del correo electrónico funciona. Haz clic en Guardar cuando hayas terminado.
Ahora que hemos configurado los canales de notificación, tenemos que configurar las alertas sobre cuándo recibir estos correos electrónicos. Para configurar las alertas, tienes que volver a los paneles del panel de control.
Haz clic en Panel >> Examinar para abrir la página del Panel.
Haz clic en el panel de control que acabamos de crear y obtendrás su página de inicio con diferentes paneles. Para editar el panel, haz clic en el nombre del panel y aparecerá un menú desplegable. Haz clic en el enlace Editar para continuar.
Haz clic en el Panel de Alertas y en el botón Crear regla de alerta desde este panel para configurar una nueva alerta.
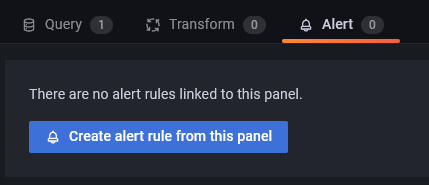
Ahora puedes configurar las condiciones en las que Grafana enviará la alerta.
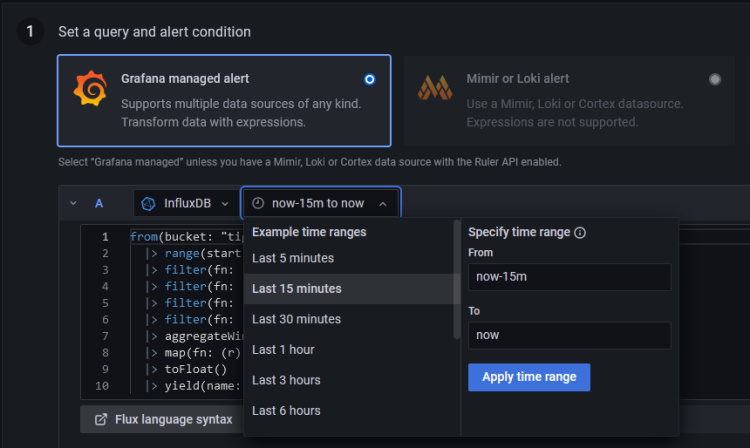
Por defecto, el tipo de alerta seleccionado es Alerta gestionada por Grafana. Haz clic en el menú desplegable para cambiar el intervalo de tiempo a Últimos 15 minutos, lo que significa que comprobará desde hace 15 minutos hasta ahora.
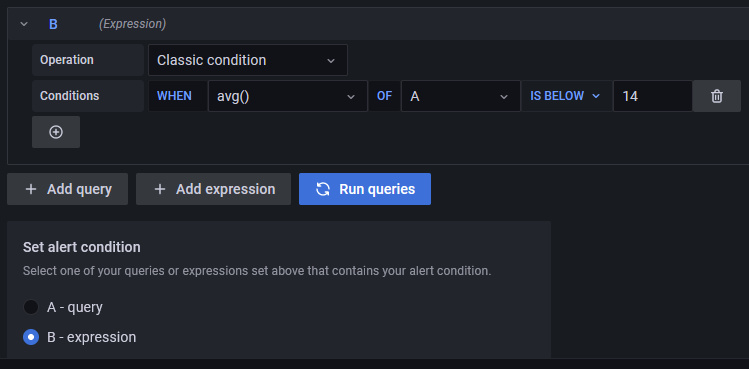
Condiciones
Grafana trabaja con una consulta del siguiente formato para determinar cuándo lanzar una alerta.
avg() OF query(A) IS BELOW 14
- avg() controla cómo debe reducirse el valor de cada serie a un valor comparable con el umbral. Puedes hacer clic en el nombre de la función para seleccionar una función diferente, como avg(), min(), max(), sum(), count(), etc.
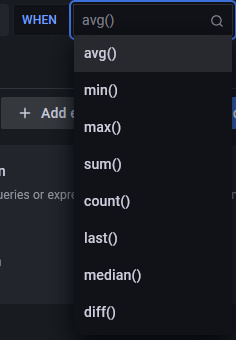
- consulta(A ) La letra del paréntesis define qué consulta ejecutar desde la pestaña Métricas.
- IS BELOW14 Define el tipo de umbral y el valor del umbral. Puedes hacer clic en IS BELOW para seleccionar un tipo de umbral diferente.

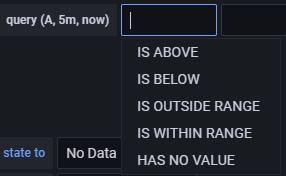
Puedes añadir una segunda condición debajo haciendo clic en el botón + situado debajo de la primera condición. Actualmente, sólo puedes utilizar los operadores Y y O entre varias condiciones.
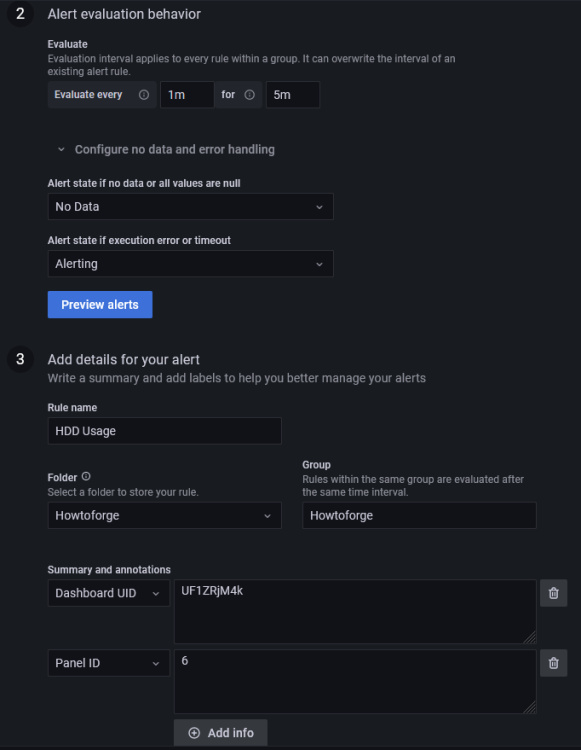
Regla
- Nombre – Introduce un nombre descriptivo para la alerta
- Carpeta – Crea o selecciona una carpeta preexistente para almacenar tu regla de notificación.
- Grupo – Introduce un nombre para tu grupo de alertas. Las alertas de un mismo grupo se evalúan después del mismo intervalo de tiempo.
- Evaluar cada – Especifica la frecuencia con la que Grafana debe evaluar la alerta. También se denomina intervalo de evaluación. Aquí puedes establecer cualquier valor que desees.
Sin datos y gestión de errores
Puedes configurar cómo debe gestionar Grafana las consultas que no devuelven datos o sólo valores nulos utilizando las siguientes condiciones:
- Sin datos – Establece el estado de la regla en
NoData - Alerta – Establece el estado de la regla en
Alerting - Ok – Establece el estado de la regla de alerta en Ok, es decir, recibirás una alerta aunque las cosas estén bien.
Puedes indicar a Grafana cómo manejar los errores de ejecución o de tiempo de espera.
- Alerta – Establece el estado de la regla en
Alerting - Ok – Establece el estado de la regla de alerta en Ok, es decir, recibirás una alerta aunque todo vaya bien.
- Error – Establece el estado de la regla de alerta en Error para indicar que hay un problema.
Cuando hayas terminado, haz clic en el botón Previsualizar alertas para ver si todo funciona correctamente. Haz clic en el botón Guardar y salir de la parte superior derecha para terminar de añadir la alerta. Ahora deberías empezar a recibir alertas en tu correo electrónico.
Conclusión
Con esto concluye el tutorial sobre la instalación y configuración de TIG Stack en un servidor basado en Ubuntu 22.04. Si tienes alguna pregunta, publícala en los comentarios a continuación.